
Introduction to EdgeDB

Summarize with AI:
EdgeDB is a Graph database that makes local development “the best I have ever seen.” See why it’s the type of database we need more of.
Imagine a scalable, secure, feature-rich Graph Database that has existed for almost 30 years. EdgeDB is just that. Postgres has been battle-tested since 1996, and now we can query it like a Graph. Beautiful.
TL;DR
EdgeDB is remarkable. You can easily create a database locally and sync it to the cloud using branching, migrations and authentication out of the box. Everything is as secure and scalable as SQL—it is just Postgres.
Installation
Here is a short summary of the Quick Start Guide.
- Install EdgeDB locally.
Windows
iwr https://ps1.edgedb.com -useb | iex
Mac
curl https://sh.edgedb.com --proto '=https' -sSf1 | sh
The installer will download the latest version and add it to your computer. You can have multiple instances for different projects installed and running.
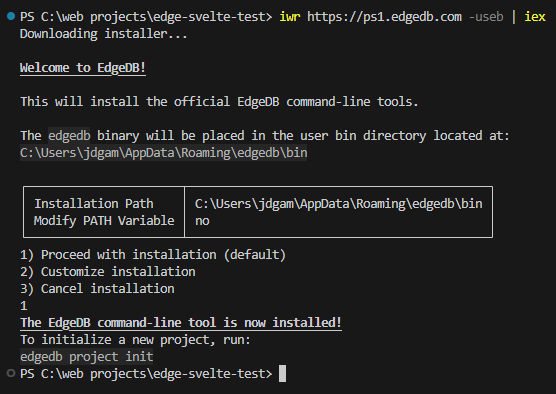
- Initialize your project as an EdgeDB project.
edgedb project init
You must name your database instance, specify the version and create a main branch.
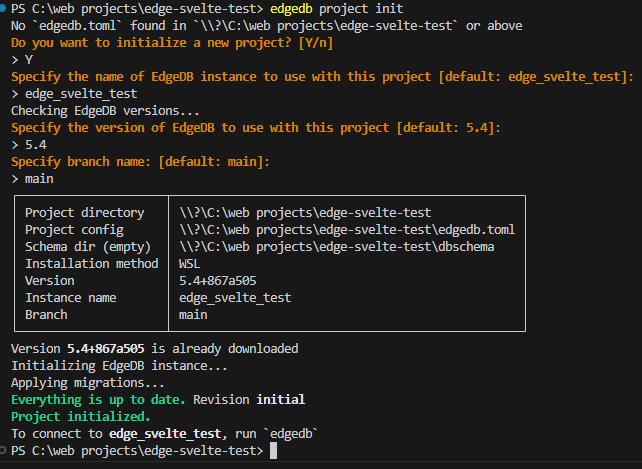
That’s it!
- Also, I suggest you install the VSCode Plugin for EdgeDB so you can see EdgeQL as it is meant to be seen.
EdgeQL
You can run the edge command line by running edgedb. Here you run EdgeQL commands just like you would sql commands. While EdgeQL is generally more concise, it is also highly advanced.
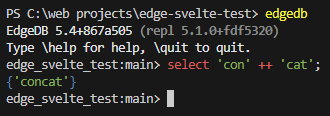
Type \q to quit.
Edge UI
EdgeDB also has a UI for viewing your database just like Supabase, Drizzle, or phpMyAdmin. You can add authentication methods or even AI plugins. Type edgedb ui.
Migration, Branches and Watch
Your default schema will be in the the dbschema/default.esdl file in your project.
module default {
}
It will be empty. Think of default as your global namespace. EdgeDB also supports inheritance types and complex abstract objects.
Migration
Edit your schema how you like, and then type edgedb migration create to create a new migration file. If you have ever used Supabase, it will be a similar process. Next type edgedb migrate to apply that migration. Your default.esdl file is now up to date.
Quick Start Example
module default {
type Person {
required name: str;
}
type Movie {
title: str;
multi actors: Person;
}
};
Branching
EdgeDB allows you to create branches with edgedb branch create branch_name. You can switch with edgedb branch switch branch_name, or even rebase with edgedb branch rebase main. Branching allows you to add features and test them, or just discard them without modifying the main database.
Watch
If you want to make changes to your schema in real time and have EdgeDB automatically detect and apply the difference, you can run edgedb watch in the background as you modify your schema in a different terminal.
Todo Example
Let’s look at a classic example, the Todo App.
module default {
type User {
required username: str {
constraint exclusive;
};
required created_at: datetime {
default := datetime_current();
};
updated_at: datetime;
multi todos := .<created_by[is Todo];
}
type Todo {
required complete: bool {
default := false;
};
required created_at: datetime {
default := datetime_current();
};
required text: str;
required created_by: User {
on target delete delete source;
};
}
};
- Here we have two main tables, or nodes:
UserandTodo. - We don’t need to create an
id, as it is automatically created with auuidtype. - We set default values inside an object-like structure.
- In this case, we can link to the
Userfrom theTodoby just setting the typeUseron the correct field,created_by. - We can set the reverse link by using a computed column. Each user can have many todos. We set it as
multi, and equal to.<created_by[is Todo];, orTodo.created_by. - We create a unique column by using
constraint exclusive. - We use cascade delete by setting
on target delete delete source. This means when a user is deleted, all their todo items are deleted.
Using this schema, you can create indexes, constraints and even function triggers. It is extremely powerful and easy to use, and it reminds you how complex SQL can be a pain.

Add a User
We can add a user one at a time.
INSERT User {
username := 'bob'
};
INSERT User {
username := 'bill'
};
INSERT User {
username := 'tom'
};
Or we can add users in bulk.
FOR username IN {'bob', 'bill', 'tom'} UNION (
INSERT User {
username := username
}
);
Add a User with a Todo
You can add a user with a todo item, but you can’t do it nested currently. Luckily, EdgeQL has a with clause like Postgres (I created a feature request for the nested insert).
WITH inserted_user := (
INSERT User {
username := 'mark'
}
)
INSERT Todo {
complete := false,
text := 'Your todo text here',
created_by := inserted_user
};
Add a Todo with a User
However, we can add a todo with a user from the reverse direction without using a with clause. This is because the type is User, not a computed type.
insert Todo {
text := 'nested insert',
created_by := (
insert User {
username := 'jon'
}
)
};
Add Multiple Todo Items with a User
We can add several todo items using a for loop after a with clause.
with user := (
insert User {
username := 'pat'
}
)
for text in {'one', 'two'} union (
insert Todo {
text := text,
created_by := user
}
);
Add a Todo with an Existing User
We simply need to find the user.
INSERT Todo {
text := 'New Todo',
complete := false,
created_by := (
SELECT User
FILTER .username = 'mark'
)
};
Select All Todos
We can easily get all the todo items just like GraphQL.
select Todo {
id,
complete,
created_by: {
id,
username
}
}
Select Todo Items Created By X
We can also easily filter the results by a nested value.
SELECT Todo {
id,
complete,
created_by: {
id,
username
}
}
FILTER .created_by.username = 'mark';
Get the Count of Results
You can count or aggregate the sum of the results just like in SQL.
SELECT count(
(SELECT Todo
FILTER .created_by.username = 'mark')
);
Get Results with Count
You can also get both at the same time. Nearly any complex query is possible.
WITH
filtered_todos := (
SELECT Todo {
id,
complete,
created_by: {
id,
username
}
}
FILTER .created_by.username = 'mark'
)
SELECT {
todos := array_agg(filtered_todos),
count := count(filtered_todos)
};
TypeScript
Finally, you can’t mention EdgeDB without mentioning its TypeScript capabilities.
npm install --save-prod edgedb
npm install --save-dev @edgedb/generate
EdgeDB has the ability to create complex typesafe queries directly in TypeScript.
import { e } from 'edgedb';
const result = await e.select(e.Todo, (todo) => ({
id: true,
complete: true,
created_by: {
id: true,
username: true,
},
filter: e.op(todo.created_by.username, '=', 'mark'),
})).run(client);
It is actually pretty beautiful. You don’t need something like Drizzle, Kysely or Prisma to run your queries. EdgeDB has a typesafe query builder out of the box!
Final Thoughts
I’m extremely ecstatic about EdgeDB. I think Graph databases should be the norm. I believe the main reason we have ORMs is due to the complexities of joins. NO MORE!
Issues and Future
Postgres handles all security and scaling issues. The problems you will encounter will be feature requests and small ORM bugs.
- They plan on adding real-time data watchers (like GraphQL Subscriptions) in the future.
- I made a feature request and hope nested inserts and updates will become easier. I would also like to handle bulk inserts like an array. 🤞🏽
- The database already handles authentication, but the documentation is weak and only a few providers are currently available. I suspect this will grow quickly.
- I don’t believe you can add Postgres extensions manually. They would need to be approved by the team and added. I’m not sure of the future of this.
Treasures
- Local development is the best I have seen. Its ease of use is only comparable to that of Supabase or Firebase, and it is still better than both of them.
- Did I mention no more joins?
- Using a schema is so much easier than using complex tables or creating statements. It just flows better.
- The database is relatively new and has an array of features built faster than any competitor I have seen.
- EdgeDB is active on social media, has a discord and has plenty of users and moderators there to help you.
This is the type of database we need in the future.

Jonathan Gamble
Jonathan Gamble has been an avid web programmer for more than 20 years. He has been building web applications as a hobby since he was 16 years old, and he received a post-bachelor’s in Computer Science from Oregon State. His real passions are language learning and playing rock piano, but he never gets away from coding. Read more from him at https://code.build/.
Related Posts
Comments
All articles
Topics
Web MobileMobile
Desktop
Design
Productivity
People
