
Handling Null Values in ASP.NET Core

Summarize with AI:
Dealing with null values is a recurring challenge in any modern web application. The good news is that ASP.NET Core is prepared to face this type of situation. In this post, we will explore the tools and best practices that help identify and prevent problems caused by null values.
Problems with null values are common in web applications that communicate with each other, constantly exchanging data. When an expected value isn’t provided, failures can occur, such as runtime exceptions or incorrect behavior.
Null values are one of the main causes of runtime exceptions in ASP.NET Core applications. A well-known example among backend developers is the dreaded NullReferenceException.
In this post, we’ll cover some key features available in ASP.NET Core to prevent common problems involving null values. We’ll also explore some best practices that help further secure a backend application, such as the null object design pattern.
🕳️ What Are Null Values?
In general programming, null values represent the absence of a value. In ASP.NET Core, which uses the C# language, null is a special value where a variable with a null value does not point to any defined object or value.
Note a common example of a variable that receives a null value:
string address = null; // The variable exists, but has no value assigned
🤔 What’s the Problem with Null Values?
When you develop an ASP.NET Core application, you are working with two main types of data: value types (like int, bool, DateTime) and reference types (like string, objects, lists, etc.).
The problem with null values mainly happens with reference types. For example, imagine that you have a Customer object, and you try to access its name like this:
var name = customer.Name;
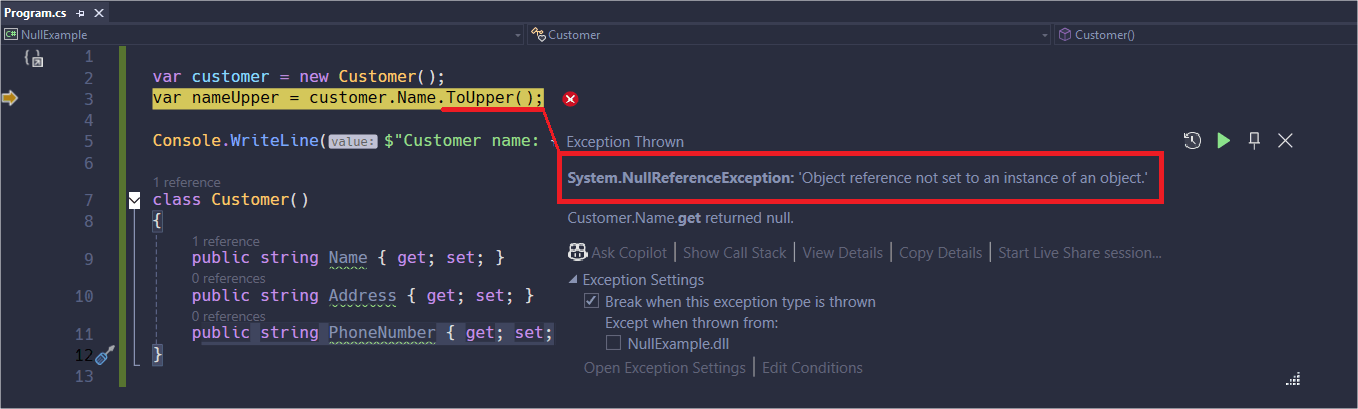
If the customer object is null, this will cause a runtime error called NullReferenceException. This error says: You are trying to access something (Name) inside an object (customer) that does not exist (is null). It is like trying to open a drawer that is not in any cabinet; you want the drawer, but the cabinet itself does not exist.
The image below shows the exception occurring in a program that aims to capitalize a customer’s name, but since the Name property is null, an exception is thrown:
🍂 Value Types vs. Reference Types
Value Types
A value type has no problem with null values, as they are not null by default. Unlike reference types, it stores the data directly, and not a reference (pointer) to the data.
Examples: int, float, double, bool, DateTime, struct (custom) are stored on the stack and contain the value directly, such as int x = 5. In this case, x stores the value 5, not a reference.
- They always have a defined value, even if it is the default value (
int = 0). - They cannot be null by default.
Reference Types
Reference types create a reference (pointer) to data. In this case, if the reference value is null and an operation is performed on it, attempting to access it will cause the runtime to throw an exception.
Examples: string, object, classes.
- They are stored on the heap, with a reference kept on the stack.
- They can point to “nothing”—that is, they can be null.
🥷 Avoiding the Uninitialized Properties Problem with Null
Uninitialized properties can cause unexpected behavior, such as the NullReferenceException. To help prevent this issue and other problems with null values related to uninitialized properties, follow these solutions:
1. Pay Attention to Warnings
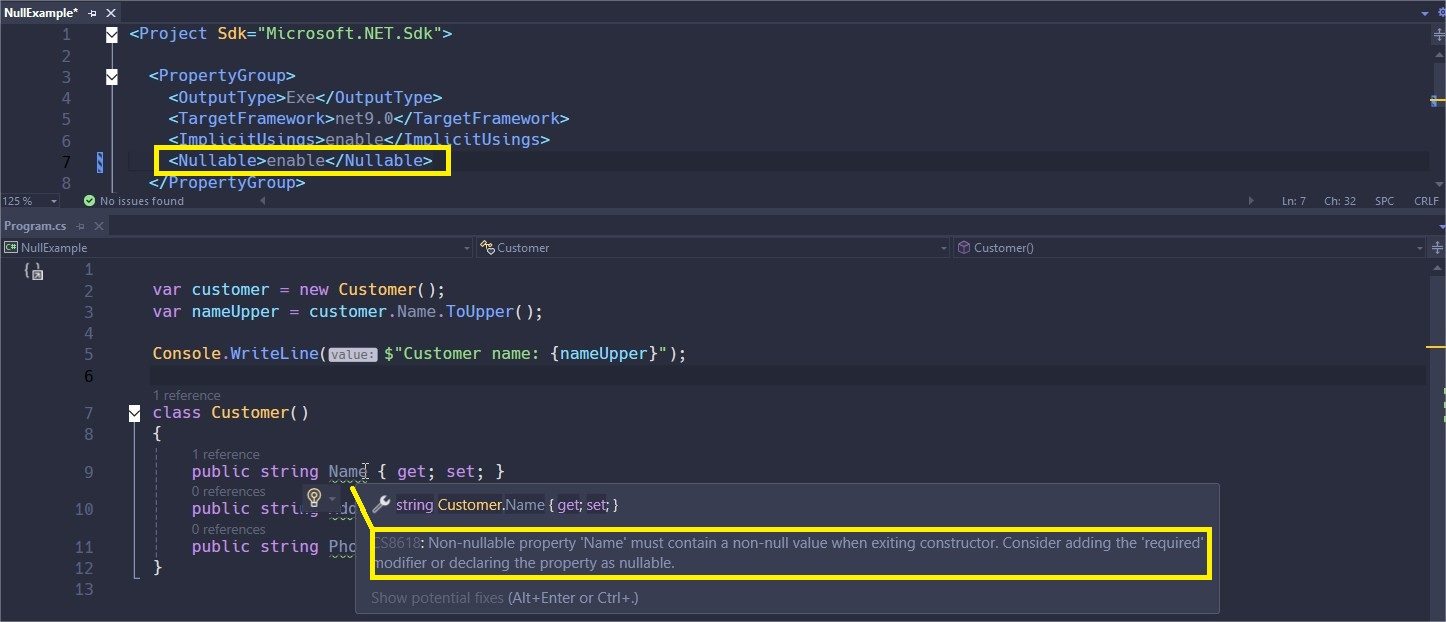
Starting with .NET 6, ASP.NET Core projects have the option to warn when uninitialized properties pose a threat, as can be seen in the image below:
2. Initialize the Properties
To solve the problem, simply initialize the properties that the warnings reported with default values, as in the example below:
public class Customer()
{
public string Name { get; set; } = string.Empty;
public string Address { get; set; } = string.Empty;
public string PhoneNumber { get; set; } = string.Empty;
}
3. Using Nullable Types
Another option is to use the nullable types to make the properties. In this case, simply add the ternary operator ? to the property. In addition, it is also possible to use the expression Nullable<T> for value types as shown in the example below:
public class Customer()
{
public string? Name { get; set; }
public Nullable<DateTime> BirthDate { get; set; }
}
4. Initializing Properties in the Constructor
Another way to avoid null reference errors is to initialize the values inside the constructor:
public class Customer
{
public Customer()
{
Name = string.Empty;
}
public string Name { get; set; }
}
5. Using the null! Operator
The expression null!, also called the null-forgiving operator, can be used to tell the compiler that this property will later be assigned a value. Note the example below:
public class Customer
{
public string Name { get; set; } = null!;
}
Using the null-forgiving operator here means that Name will be assigned correctly later (in a constructor, factory method, etc.), so it should not throw nullability warnings.
But be careful! The null! operator still assigns null at runtime, which can cause a NullReferenceException if you try to use the property before assigning it correctly.
6. Using required Modifier
The required modification operator is available as of C# 11 and can be used to ensure that the property is initialized when creating a new instance of the class, as demonstrated in the example below:
var customer = new Customer
{
Name = "John"
};
public class Customer
{
public required string Name { get; set; }
}
💎 Best Practice: The Null Object Pattern
In addition to the features available natively in ASP.NET Core, there are some principles and best practices that we can follow to mitigate the risks and problems caused by unhandled null values. One of the main initiatives is the design pattern known as the null object.
Null object is a design pattern that proposes the use of a null object (representing “nothing”), but which is still functional.
Instead of returning null and having to check for it at every point in the code, you return a “do-nothing” object in a safe and controlled way. This null object implements the same interface as the real object, but its behavior is neutral or empty.
Some advantages of using this pattern include eliminating null checks, reducing the risk of NullReferenceException, making the code cleaner and with fewer ifs, and following the principle of polymorphism.
Practicing Null Object Pattern
To see how a null object is used in practice, we will create a simple API that will have an endpoint to receive a message, and if the message is not null, it should log it. If it is null, it should do nothing. However, the first version will show how this would be done without using the null object pattern, and the second version will use the pattern.
You can check the complete source code in this GitHub repository: Order Log Source Code.
To create the application, you can use the command below:
dotnet new web -o OrderLog
❌ Without the Null Object Pattern
Open the application and create a new folder called “Services” and, inside it, add the following class:
public class LoggingService
{
public void Log(string message)
{
Console.WriteLine($"[LOG]: {message}");
}
}
Here, we just created a service class to display a message received as a parameter on the console.
Now in the Program.cs class, add the following code:
app.MapPost("/", ([FromServices] LoggingService service, [FromBody] string message) =>
{
if (message != null)
{
service.Log(message);
}
return Results.Ok();
});
Note that in this implementation of the endpoint, a null check is performed on the message received in the parameter, and if it is not null, it calls the method that logs the message.
💡 The problem here is that when working with parameters and variables with null values, we run the risk of causing the NullReferenceException exception. In addition, the code becomes dirty as the number of null validations increases.
✅ Using the Null Object Pattern
To avoid problems with null values, we will refactor the code to implement the null object pattern.
To do this, we will create two objects. The first to log the message and the second to use the null case—that is, if the message is null, it does nothing. Both objects will implement the same interface, but each in its way.
So, inside the Services folder, add the following interface:
namespace OrderLog.Services;
public interface ILoggingService
{
void Log(string? message);
}
Note that we only declare the necessary method that will bind the message. In addition, we use the ternary operator ? to indicate that the message may receive a null value.
The next step is to create the classes. Add the following class, which will be the real implementation of the log:
namespace OrderLog.Services;
public class ConsoleLoggingService : ILoggingService
{
public void Log(string? message)
{
Console.WriteLine($"[LOG]: {message}");
}
}
Then add the class that will implement the null scenario—that is, it will do nothing.
namespace OrderLog.Services;
public class NullLoggingService : ILoggingService
{
public void Log(string? message)
{
// Do nothing
}
}
Now, let’s refactor the Program class that will decide which scenario to execute based on the message value. Therefore, replace the Program class code with the following:
using Microsoft.AspNetCore.Mvc;
using OrderLog.Services;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddScoped<LoggingService>();
builder.Services.AddScoped<NullLoggingService>();
var app = builder.Build();
app.MapPost("/", (
[FromServices] LoggingService realService,
[FromServices] NullLoggingService nullService,
[FromBody] string? message) =>
{
ILoggingService service = message is not null ? realService : nullService;
service.Log(message);
return Results.Ok();
});
app.Run();
💡 Notice that we now have two logging service objects: one is the real one, which will display the logging message, while the other will consider the null value. By doing this, we have an elegant way to handle null cases, where we anticipate potential problems and use the null object pattern.
Now we no longer have the if null check. We just call the service class, and everything is perfectly resolved in it.
🔥 Running the Application
Now let’s run the application and make two requests to verify that the objects will react correctly depending on the value sent in the request.
So, first, we execute a request to the API, sending a value to the message property.
Endpoint: POST - https://localhost:7141
Body:
"Payment made successfully"
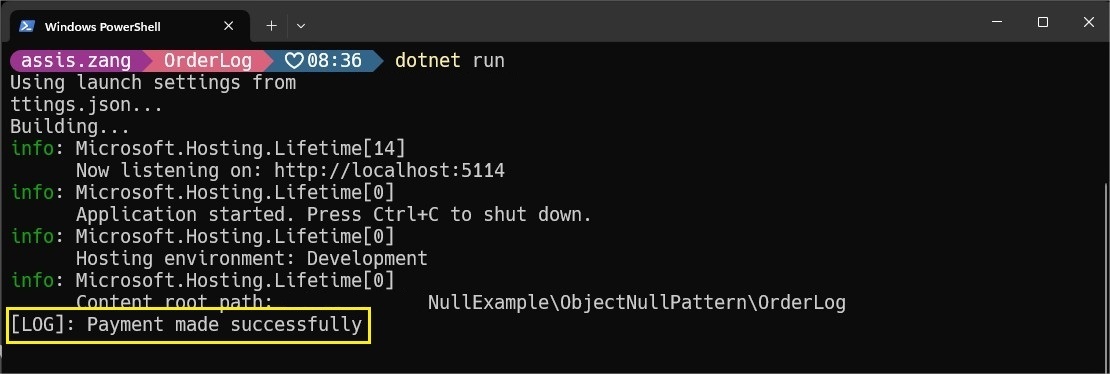
Since the message will not be null, the real service will be used, and the log message will appear in the console:
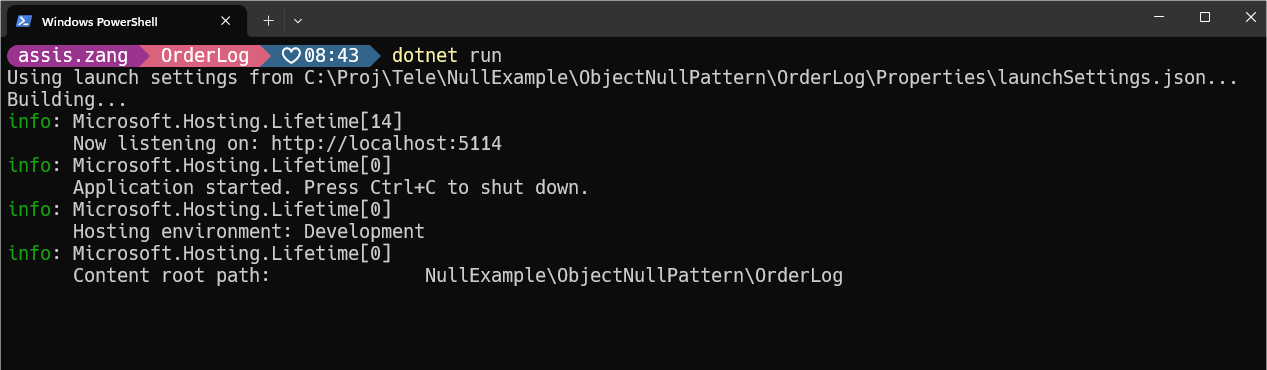
Now, make the same request, but this time without sending anything in the body. This time, the null object will be used, so nothing will be logged to the console:
✨ Conclusion
I hope this post helps you resolve common problems with null values when creating something new in ASP.NET Core!

Related Posts
Comments
All articles
Topics
Web MobileMobile
Desktop
Design
Productivity
People
