
What Are RAG Embeddings?

Summarize with AI:
Embeddings translate text into numerical vectors to plot semantic meaning. This allows RAG systems to find semantically similar concepts even when the words are different.
In our previous article on Retrieval-Augmented Generation (RAG), we explored how RAG solves a critical problem with standard LLMs.
LLMs can only work with information from their training data, but organizations need AI assistants that can answer questions about their internal documentation. RAG solves this by retrieving relevant documents from a knowledge base and using them to augment the LLM’s response.
In the previous article, we mentioned that retrieval systems rely on embeddings to find semantically similar content. But what exactly are embeddings, and how do they enable systems to understand that “authentication” and “login security” are related concepts even though they use completely different words?
In this article, we’ll unpack how embeddings work, why they’re essential for systems like RAG, and how they allow AI models to “understand” meaning in a mathematical sense.
Embeddings
At its core, an embedding is a way of representing text as a list of numbers, specifically, a vector of floating-point numbers.
Think of it like a coordinate system for language. Just as a GPS coordinate (42.3601, -71.0589) pinpoints a specific location on a map, an embedding vector like [-0.0069, -0.0053, ...] pinpoints a piece of text in a high-dimensional “meaning space.”
Texts with similar meanings produce vectors that are mathematically close to each other, while texts with different meanings produce vectors that are far apart.
How Embeddings Capture Meaning
Traditional keyword-based search systems struggle with semantic relationships. If you search for “authentication,” they won’t find documents about “login security” unless those exact words appear. Embeddings solve this problem by capturing the underlying meaning rather than just matching words.
This is made possible through embedding models (e.g., OpenAI, Gemini, Nvidia, etc.), which are specialized neural networks trained to map text, code or even images into a shared vector space where meaning determines proximity. These models are what give AI systems the ability to recognize that “login security,” “user verification” and “authentication” all describe similar ideas, even though the phrasing differs.
When an embedding model processes text, it analyzes the context in which words appear, their relationships to other words and the overall semantic structure of the text. The model has been trained on vast amounts of text data, learning patterns about how concepts relate to each other. As a result, it can produce numerical representations that reflect these learned relationships.
For example, consider these three sentences:
- “The user needs to authenticate before accessing the system.”
- “Login security requires multi-factor verification.”
- “The weather forecast predicts rain tomorrow.”
An embedding model would produce vectors for each sentence. The first two vectors would be mathematically similar (close together) because they’re about authentication and security, even though they share no common words. The third vector would be far from the other two because it deals with an entirely different topic.
The distance between two embedding vectors measures their relatedness. Small distances suggest high relatedness, while large distances suggest low relatedness.
RAG systems typically use cosine similarity to measure this distance. Cosine similarity compares the angle between vectors rather than their absolute distance, returning a value between -1 and 1 where values close to 1 indicate high similarity. This is why embeddings are so powerful for semantic search: They can find relevant content based on meaning, not just keyword matching.
Getting Embeddings from an API
Most teams don’t build their own embedding models from scratch. Instead, they use embedding services provided by companies like OpenAI, which offer pretrained models that have learned semantic relationships from massive datasets.
Obtaining an embedding can be straightforward. When working with APIs, you send your text to the embeddings endpoint along with the model name, and you receive a vector of numbers in return. Here’s how you’d do it in JavaScript using OpenAI’s API:
import OpenAI from "openai";
const openai = new OpenAI();
const embedding = await openai.embeddings.create({
model: "text-embedding-3-small",
input: "Our API rate-limiting policy enforces 1000 requests per minute for standard tier clients.",
encoding_format: "float",
});
console.log(embedding.data[0].embedding);
The response contains the embedding vector along with metadata:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
0.0191497802734375,
-0.010498046875,
-0.019439697265625,
-0.01496124267578125,
...
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
That long list of numbers is the embedding vector (we’re just showing a small subset of that in the above response example). For OpenAI’s text-embedding-3-small model, the vector has 1536 dimensions by default (meaning it’s a list of 1536 numbers). Each dimension captures a specific aspect of the text’s meaning, and together they form a comprehensive semantic representation.
Once you have embedding vectors, you’ll need a way to store them and search through them efficiently. That’s where vector databases come in.
Vector Databases
A vector database is a specialized database designed to store and query high-dimensional vectors efficiently. Unlike traditional databases that search for exact matches or simple keywords, vector databases excel at finding similar vectors using distance metrics, such as cosine similarity.
When you’re building a RAG system, you’ll typically:
- Index your documents: Convert each document (or chunk) into an embedding and store it in the vector database along with the original text and any metadata.
- Query for similar content: When a user asks a question, convert the question to an embedding, then search the vector database for the most similar document embeddings.
- Retrieve the originals: Use the similarity scores to rank results and retrieve the original text from the most relevant documents.
The key advantage of vector databases is their ability to perform fast similarity searches across millions of vectors. They utilize techniques such as approximate nearest neighbor (ANN) algorithms to make these searches efficient, even at scale.
Progress Agentic RAG
Building a RAG system from scratch requires setting up embedding models, vector databases, indexing pipelines and retrieval logic, all of which can take significant time and engineering effort. Progress Agentic RAG streamlines this process with a no-code, SaaS approach, providing you with immediate access to RAG capabilities.
Index your files and documents, and the platform handles the rest, automatically converting your content into embeddings and making it searchable.
One particularly cool feature with Progress Agentic RAG is the ability to use multiple embedding models simultaneously. You can even add different embedding models to your knowledge base via API, and every new resource you add will be processed with all your configured models. This lets you test and compare how different models perform on your actual data without committing to a single choice upfront.
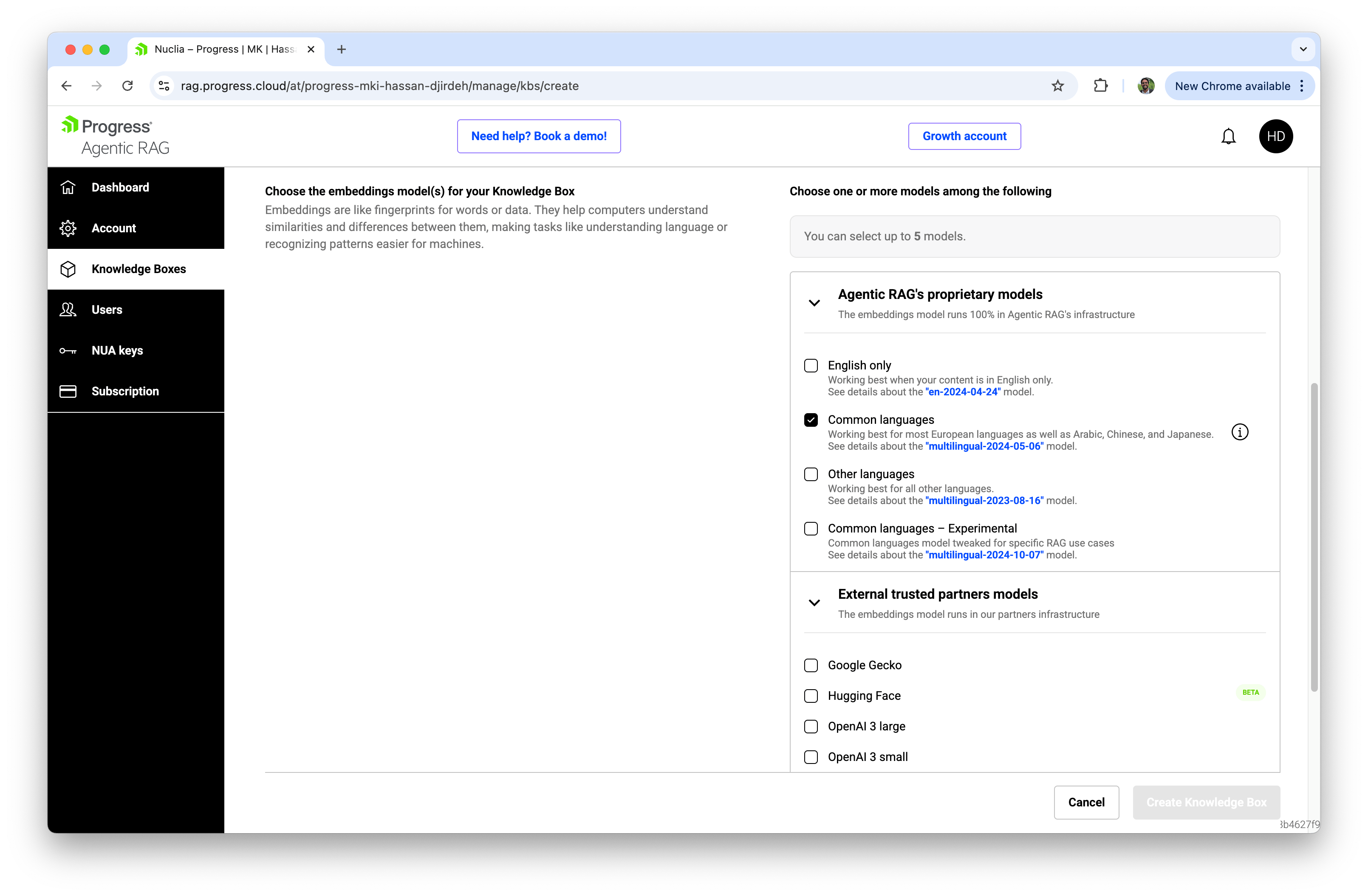
Progress Agentic RAG is powered by NucliaDB, which goes beyond traditional vector databases by unifying semantic search, keyword search, metadata search and knowledge graph traversal. This provides richer context and better traceability than standard vector databases, making it more suitable for RAG systems that require delivering accurate and verifiable answers.
Wrap-up
Embeddings transform text into numerical representations that capture semantic meaning. They’re the foundation that makes semantic search possible allowing RAG systems to retrieve relevant context from large knowledge bases efficiently. For more details, be sure to check out the following resources:
- Progress Agentic RAG
- Embeddings models | Progress® Agentic RAG
- Playing with different embedding models | Progress Agentic RAG
Keep reading this series of RAG posts:

Hassan Djirdeh
Hassan is a senior frontend engineer and has helped build large production applications at-scale at organizations like Doordash, Instacart and Shopify. Hassan is also a published author and course instructor where he’s helped thousands of students learn in-depth frontend engineering skills like React, Vue, TypeScript, and GraphQL.
Related Posts
Comments
All articles
Topics
Web MobileMobile
Desktop
Design
Productivity
People
