
.NET - The Bad Parts

Summarize with AI:
In many ways, working as a developer is kind of like going to war. There are victories, there are casualties, there are often heroic songs sung by the campfire, but at the end of the day every project, just like every war, will sink or swim based on the decisions made by the people involved.
Historically speaking, wars have been started by kings and queens but led by generals. Those generals do their best to assess the landscape and make informed decisions that will provide the most benefit to their side or do the least harm to their forces to accomplish a given goal. On the flipside, the generals are often not the ones in the trenches doing the actual work, which is where the foot soldiers come in, making the minute-to-minute decisions on how to respond while on the front lines.
Obviously, most development does not involve swords and bombs, but the structure is very similar. Key decision makers lead a project, project managers oversee the big picture and often have architectural and tooling input, and the everyday developer is responsible for implementation and making the small but important day-to-day decisions that could turn the tide of a project.
Wait a minute - isn't this article about .NET development? There is a reason for the references to war, sinking or swimming, and the overall org structures that have persisted over time. That reason? The Spanish Armada.
The Spanish What?
While I have managed to find a lot of developers at conferences who are also history buffs, I won't assume you know the story of the Spanish Armada. Or more likely, if you've heard the short and horribly inaccurate story of the armada or seen a film version that leaves out the small but important details. I'll spare the part about the 16th century balance of power in Europe, as fascinating as it may be, and focus on the important part for our purposes. The armada had the goal of transporting an army that would hopefully crush England, but through a series of unfortunate events and decisions history saw another version of this unfold.
After they were already routed once by Sir Francis Drake, the Armada needed to wait for further communication from the Duke of Parma regarding next steps. Unfortunately the Duke of Parma was blocked in harbor by the Dutch, providing the English time to attack the fleet with fireships (they are as cool as they sound), resulting in another battle and sending the Armada even further from their intended course. Being held at bay by the English navy, the Armada attempted to sail around England and attack from the north, but an unforeseen and tragic storm pummeled the fleet, forcing it to abandon the task to take England and returning to Spain after losing over 1/3 of their 130 ships.
A few things happened here. First, a lack of communication between fleets ultimately led to the demise of the armada. The lack of communication was caused by a blockade, filling the entrance to the harbor so nothing could get through. On top of that, while the Spanish were at sea they had little feedback as to conditions around them, so something as simple as a modern weather report could have tipped the tide of history as the storm could have been avoided. Understanding their environment would have been a game changer.
.NET and Communication
Normally when people are discussing communication in .NET, topics like service layers, JSON, and protocols are usually the first things to come to mind. But what about communication within .NET? Surprisingly enough, there is a lot that happens under the covers when you want to run something like a WPF application.
In a nutshell, WPF and .NET are two separate frameworks. They mesh together seamlessly, but much like you can have a Winforms or MVC .NET Application, WPF represents another paradigm for development as well as a presentation layer. The key differentiator between how Winforms and WPF handle graphics lies in the difference between immediate and retained mode graphics. Winforms uses immediate mode, requiring the application itself to handle the redraw requests through a loop between the application and Windows to render GDI output that is placed on the screen. Alternatively, WPF offers retained mode graphics, unloading all of the visuals to the system to allow it to handle rendering through the GPU or other system graphics pipeline. Much like any pipeline, however, blockages happen.
You Shall Not Pass!
Back to our friend the Duke of Parma, we can see a good example of how a graphics pipeline should work and how to stop one cold. Normally a harbor operates such that ships can pass in and out via shipping lanes, each being respectful of one another and allowing safe passage. The Dutch had other plans, creating a full blockade of the harbor so that no ships could get through. But what does this mean for the WPF developer?
The WPF graphics pipeline works kind of like a harbor or other type of transit system. As long as items flow at a measured pace, everyone can play nicely and everyone gets where they are going on time. But when there is congestion of any sort in the pipeline, things can get ugly. One of the problems a WPF developer runs into from time to time is pushing too much to the graphics pipeline too quickly. I won't get into the technicalities of what this is doing on the hardware side, but the end result is trying to shove a hundred square pegs through a square hole. At the same time. Then adding more square pegs before that hundred gets through.
In development terms, it's almost like the code reaching running on the UI thread puts a lock on visual updates until it can complete *just this one operation*, but before that finishes another operation begins on the thread and it then has *just this one new operation* to complete before rendering. Multiply this by the framework code for measuring, arranging, sizing and resizing, all on each render pass, and you effectively blockade yourself from rendering UI until your dog pile of UI operations is complete. Even worse, as WPF developers it is very easy to get carried away by the lure of having desktop hardware to run on and loading up our interfaces with tons of animating widgets because we can but not because we should. Dancing hamsters were all the rage on the early internet at one point (I was there), but that doesn't mean they were a great idea. Animated gif flames on either side of your page title, however…
Visual and Logical Trees
We've been discussing the UI layer and how the UI thread interacts with lots of elements, but the UI thread is only a part of the greater scope of things a WPF developer needs to understand about the good and bad of .NET. We know now that there is a system in place for handling graphics, so a bit of a leap from the old Winforms days where an app manages its own drawing, but there is a big gap between the C# we're writing and the visuals that users are interacting with. Backing up a little we can see the greater concept of the presentation layer, the point where WPF diverges from .NET to WPF-specific operations.
In working with the presentation layer, a WPF developer is primarily concerned with the Logical and Visual trees. (If you don't know what these are, this section on MSDN is a must for you! We'll wait until you get back.) These two closely correspond, usually on a 1:1 basis between object and visual to represent the object, but there are distinct differences that need to be understood in order to fully take advantage of the framework.
First we have the Logical Tree. If you're touching C# or VB, you're already working with it - it's the object graph of everything running or accessible in your application. The main Application, your main Window, any UserControls or Custom Controls you're working with in code are part of the logical flow of objects and operations within your application => the Logical Tree. The nice thing here is that a list of objects requires nothing but that list of objects to exist and can be manipulated as a list of objects. Take for example our very simple class here:
public class TreeClass
{
public int Id { get; set; }
public string Name { get; set; }
public ObservableCollection<TreeClass> ChildTrees { get; set; }
public TreeClass()
{
ChildTrees = new ObservableCollection<TreeClass>();
}
}TreeView control to get this result at runtime:
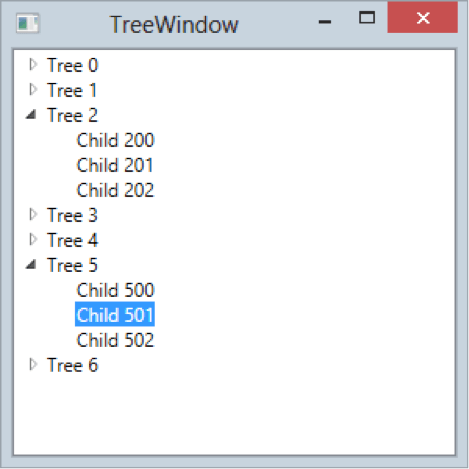
If you had to correlate the items in the above tree to the items generated for our previously mentioned TreeClass, you might see a pretty direct relation. Looks like we're displaying the Name property from the object and the children are coming from the ChildTrees collection through a hierarchical datatemplate, but still pretty 1:1. Right?
Sort of. We're now working with the Visual Tree, the actual derived representations of our objects based on styles and templates and rendered through that graphics subsystem discussed earlier in the article. To get even more verbose, we're passing a structure of objects, in this case defined by an ObservableCollection<T>, to our UI the by setting the ItemsSource property of the TreeView. This tells the TreeView that it can bind to the data in the underlying collection via property paths for ultimately displaying data as well as derived visuals based on the data through conversion. But this all happens via the binding framework. If we had to use some developer art to represent this, our 1:1 actually looks a bit more like the following:
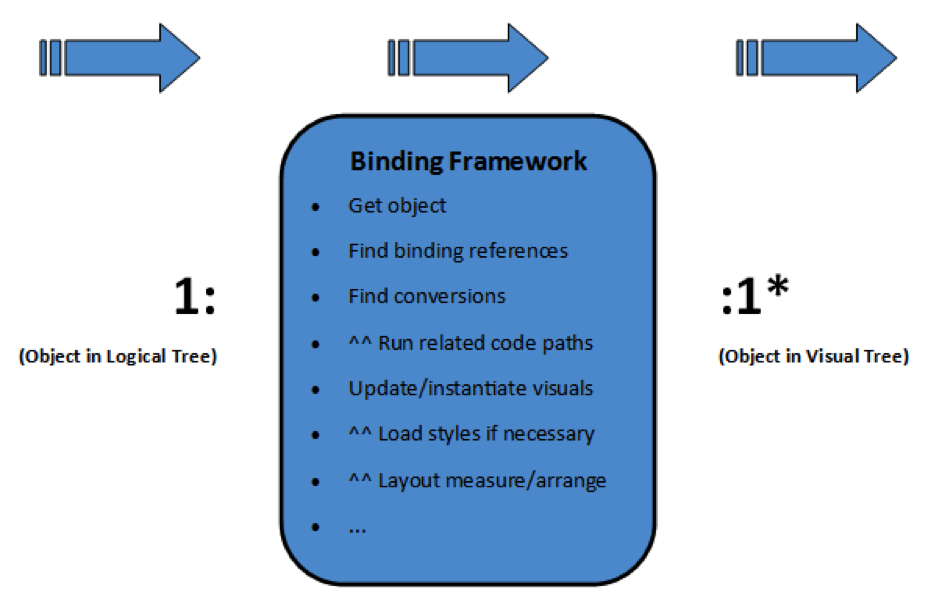
As it turns out, there is a LOT happening in our simple 1:1 correlation between object and treeview item. And did you notice that * on the right-hand side of our diagram? That's where we get to the really fun part, since you have a single object but the visual framework allows for multiple bindings to the same object, your single object could be tied to one, ten, or even a hundred UI elements. I wouldn't recommend this, but sometimes you will see a single object tied to two or three visual elements for different reasons, like a TextBlock to display one value while the value is passed via conversion to other elements for picking styles or other visual effects/modifications. That's okay - this is how the folks who wrote the framework intend for you to use the binding engine. Rather than a bunch of Button.Click or TextBox.TextChanged events, we bind objects to the UI so the system can handle communication back and forth and we don't have to write an event handler for every possible bit of UI interaction a user can perform.
But with great power comes great responsibility.
Don't Cross the Streams!
Now that we know how the visual and logical trees work we can talk about what doesn't work. Or more specifically, what will technically work but you should avoid at all costs for performance and usability reasons. If you get the reference from this section title you're one step ahead - don't cross the Visual and Logical trees (if you can avoid it).
The issue exists at the core of what the Logical and Visual trees are really responsible for. Your Logical tree can likely run in a console application the same as it runs in WPF, albeit with some UI tweaks, but otherwise the logic is pure .NET development code. The Visual tree takes care of everything interacting with the graphics subsystem, so detecting the screen, positioning your window, and little things like measuring, arranging, and drawing every visual object on screen. The Logical tree exists insofar as what objects you have loaded in memory to represent your application structure and logic at any point in time (and can remain completely dormant if no logic is being processed). The Visual tree exists for displaying elements on screen for the user, being built up from the root element every time it needs to be referenced to determine the exact state of any given element.
Remember that '1:1' binding diagram? In essence, every time you reach out and touch the Visual tree from the Logical tree every point from root to the object you're looking for needs to go through that full cycle to get the real-time state information that you're trying to access. The impact may not be dramatic if you're reaching out and modifying a single TextBox, but try this in a loop going through every element of a deeply nested hierarchical treeview and you may start seeing issues.
To demonstrate this, we're going to code up a small example to demonstrate the impact of crossing the streams.
Scrolling With a Purpose
We will start our example with a basic WPF application. In our case I am using the same solution for all demos in this article, so the full source code for the examples can be found on Github. Our initial setup is going to be relatively simple and can be expressed pretty easily with a few bullets:
- UserControl (root)
- Grid
- [Column]
- Buttons for example interaction
- TextBlocks to display values for debugging
- [Column]
- ScrollBar for group scrolling
- [Column]
- ScrollViewer
- StackPanel (horizontal)
- ScrollViewer
- [Column]
Here's one part of the code that is extra important to highlight:
<ScrollViewer x:Name="GridScrollViewer"
Grid.Column="2"
MaxHeight="10000"
MaxWidth="10000"
HorizontalScrollBarVisibility="Auto"
VerticalScrollBarVisibility="Disabled">
<StackPanel x:Name="GridStackPanel"
Orientation="Horizontal"
MaxHeight="9000"
MaxWidth="9000" />
</ScrollViewer>
Back on track, we create a new UserControl to house nothing but a RadGridView instance that populates itself with data. There's nothing really new here, so you can see the code in CustomControls/SelfContainedGrid. To our purpose, this SelfContainedGrid control is going to load a RadGridView instance with 180 records and custom-defined columns that include an overridden cell template to show a RadDataBar instead of a vanilla number value in one of the cells. This is obviously not real-world data, but adding those little complexities helps get our example a little closer to a real-life application and makes the test we perform a little more accurate.
Returning to our main UserControl, we add a button that creates a new instance of SelfContainedGrid and adds it to the GridStackPanel. With this setup we can scale our visuals easily to test performance when one, two, or even four controls are showing. This next step requires a little bit of knowledge of the inner-working of RadGridView, so I'll give you a shortcut. RadGridView acts as a shell with an engine for a GridViewScrollViewer component that has our rendering area as well as scroll bars to translate the visible area - like scrollbars do. Since we want to enable group scrolling for N-SelfContainedGrid instances we will grab an instance of our GridViewScrollViewer, ensure the ScrollBar that it contains for vertical scrolling is hidden, and finally update the vertical scroll value with the new value from the scrollbar. Sounds easy enough, so here's the code to do that (for reference, the scrollTo double is just e.NewValue being passed from the ScrollBar we're using):
private void scrollGrids(double scrollTo)
{
var radGrids = GridStackPanel.ChildrenOfType<RadGridView>();
double tempMax = 0.0d;
foreach (RadGridView rgv in radGrids)
{
var scrollViewer = rgv.ChildrenOfType<GridViewScrollViewer>().FirstOrDefault();
if (scrollViewer != null)
{
ScrollBar sb = scrollViewer.ChildrenOfType<ScrollBar>().FirstOrDefault(x => x.Orientation == Orientation.Vertical);
if (sb != null)
{
if (sb.Maximum > tempMax)
{
tempMax = sb.Maximum;
}
sb.Visibility = Visibility.Collapsed;
}
scrollViewer.ScrollToVerticalOffset(getModValue(scrollTo, tempMax));
}
}
}
Before the bad news, we'll add some instance variables to perform rough analytics on how many times these things are being hit. On the ScrollBar.ValueChanged event we'll iterate one value, while we'll use any call to ChildrenOfType to count hits on the Visual tree. I want to do this scientifically, so I'll start with one SelfContainedGrid and scroll from top to bottom three complete times over about thirty seconds. Then for two, three, and four grids I'll do the same to target the same number of value changed hits. The numbers speak for themselves:
| Value Changed Event Hits | Visual Tree Hits | |
| 1 | 827 | 2481 |
| 2 | 825 | 4125 |
| 3 | 825 | 5775 |
| 4 | 828 | 7452 |
As you can see, the number of Visual tree hits does scale and gets quite dramatic with multiple grids being displayed. I highlighted the last two rows because at three SelfContainedGrid instances we start seeing the UI bottleneck start, at six or seven grids you're performing the full blockade on the UI thread because there are so many calls hitting it that it cannot get an update out to the user. Even worse is the fact that this is a demo, so we're not talking about network calls, hits to the database, conditional logic, extra conditional templates for items scrolling in and out of view, etc., so in a real production application with business requirements and [angry] end users "scroll slowly" just won't cut it for a solution.
Abandon Ship! The Business Users are Coming!
Just kidding - all hope is not lost. Since we're now enlightened WPF developers and not just carrying Winforms habits over to the new framework, we know a few things about how our UI is created, the processes involved with the binding framework, and the impact of hitting the Visual Tree too many times from the Logical tree. Despite numerous requests to management we cannot change the behavior of our end users, so let's see what the framework can do for us to fix the problem we've dug ourselves into with our amazing new multi-SelfContainedGrid display.
Looking back at our code, the real culprit seems to be the calls to Child/ChildrenOfType style extensions that trace the Visual tree. From the code sample you can see that we're running this same code for identifying RadGridView, GridViewScrollViewer, and the contained vertical ScrollBar on every tick of the core ScrollBar control, but what we really want to happen is to simply update the vertical scroll position when the main scrollbar is moved. Everything else is essentially setup code. Plus, once you grab a reference to an object in the Visual tree, provided that object doesn't leave the Visual tree, you can store that visual in an instance variable and reference it later. This means we can refactor all of that lookup code to instead generate a collection of GridViewScrollViewers, then loop through that collection and update values when the scrollbar moves.
Check out the Views/SyncGrids UserControl in the solution. Before you start scrolling, load up four grids via the button on the UI and click the 'Sync' button. This will run our lookup code and hide the vertical scrollbars for each grid for us, but the magic is in the value changes and visual tree lookups. Before ever touching our scrollbar, we've got 9 lookups and 0 value changes. After running the scrollbar into the area of ~825 value changes, we're still at only 9 Visual tree lookups. On top of that, the scrolling speed has increased dramatically for four grids, staying much more responsive to the location of the scroll thumb. Now that's what I call code re-use - tweaking the offending code so that only a few changes dramatically increase performance, all because we understand the impact of reaching so frequently between the Visual and Logical trees.
The Bad Parts Make Us Better Developers
Circling back to our earlier history lesson, we see that problems which plagued the Spanish Armada centuries ago are the same types of problems we face as developers today. Effective communication is key in any scenario, but understanding the nature of that communication is where an informed developer can take a blockade and turn it into usable UI. Yes WPF is .NET and a lot of .NET works nicely with WPF, but far too many developers take the "throw it at the UI thread" approach without realizing the complexities that go into the Visual and Logical trees as well as the binding framework… and how a few poor choices can dramatically impact both your application and performance for end users.
At the end of the day, understanding the framework is essential for developers who are building large-scale, enterprise applications - it's can mean the difference between performance clouds on the horizon and getting swallowed up in the storm.
Resources
MSDN - Trees in WPF http://msdn.microsoft.com/en-us/library/ms753391(v=vs.110).aspx
MSDN - WPF Data Binding http://msdn.microsoft.com/en-us/vstudio/ms750612(VS.110)
Telerik - UI for WPF, RadGridView Virtualization http://www.telerik.com/help/wpf/radgridview-features-ui-virtualization.html
Telerik - UI for WPF, Performance How-To Info http://www.telerik.com/help/wpf/gridview-troubleshooting-performance.html

Evan Hutnick
Evan Hutnick works as a Developer Evangelist for Telerik specializing in Silverlight and WPF in addition to being a Microsoft MVP for Silverlight. After years as a development enthusiast in .Net technologies, he has been able to excel in XAML development helping to provide samples and expertise in these cutting edge technologies. You can find him on Twitter @EvanHutnick.