
Machine Learning for Developers

Summarize with AI:
As Machine Learning (ML) becomes mainstream in the software industry it's important to understand how it works and it's place in the development stack. With a firm understanding of how to build a ML service for your application, you can identify opportunities in your applications for ML, implement ML, and communicate clearly with ML professionals on your team.
Throughout the series we'll build a ML service for predicting loan approval based on credit history, create a web service, and consume the web service from various platforms. Through this process we'll learn about Microsoft Azure ML Studio, a ML tool for building custom ML services. For the first part of the series we'll focus on how to build a Training Experiment, understand the basics of Azure ML studio, and experience the process of building a predictive model.
Let's begin by discuss how ML relates to the application stack.
If you want to understand some of the core concepts of machine learning, check out my prior article, What Is Machine Learning.
The Big Picture
Modern application architecture generally consists of multiple tiers. At the very basic level these separations are between the server and client application code. The server code may be separated into additional features or services. Azure ML provides an additional service to the application through web services.
Azure ML services are REST API and JSON formatted messages that can be consumed by a wide range of devices and platforms. These web services are secured through a private API key, thus exposing these services to some clients require a server layer to mediate between the client. Additionally, some applications may require additional processes, validation, or authentication to run in-between the client and service.
Learning the Full Stack
Understanding the role of ML in an application can be beneficial to full stack developers. Full stack developers, as the term implies, are often tasked with building a variety of application services. While development using Azure ML differs from writing code, developers will find familiar concepts and tools for writing SQL and R code.
Learning the structure of Azure ML services will give developers a foundation for communicating with their development team. There are opportunities to increase the quality of services built using ML if everyone involved understands the system, its inputs and outputs, and terminology used with the platform. Design decisions made at the ML layer can effect the entire application all the way through to the user interface.
Training Experiment Basics
Working with Azure ML is a very structured process. We'll begin with collecting and analyzing data which will be used to train the predictive model. Next, the data must be cleaned of all anomalies, missing data points and outliers.
Once the data is prepared, we'll split the data into groups for training and testing. The training data is used by a machine learning algorithm to create a predictive model which is validated against the test data. After the model has been finalized, we can create a predictive model and generate web endpoints for processing data.
To begin creating a new experiment with Azure ML studio, click new then choose Experiments, Blank Experiment from the menu. Once the new experiment is created an empty experiment outline is displayed showing the basic work flow of an experiment.
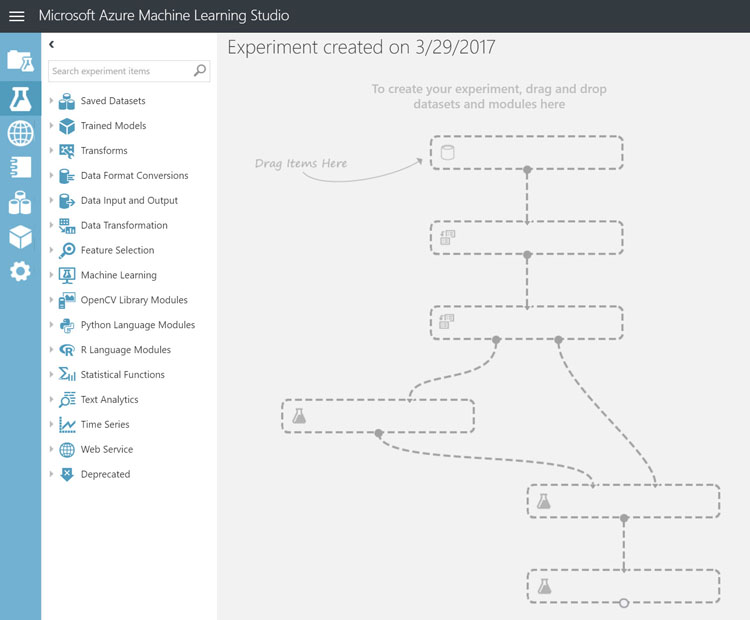
The outline shown is a representation of how the process of building a model flows.
Throughout this process we'll be dragging modules from the experiment items on the left and dropping them into the experiment work surface on the right. Each module is then connected to the inputs and outputs of other modules to perform tasks such as: data cleaning / transformation, selecting machine learning algorithms, model scoring, and web endpoints. Upon running each module, the output can be visualized by right-clicking on the module and selecting visualize from the menu.
Preparing Data
This process starts by analyzing and cleaning large sets of data. ML relies on large sets of data that are analyzed to identify patterns, with more data will yielding better results. It's important to have a good understanding of the data, and what data points are key factors in producing a good predictive model. This may require working with individuals who are experts in the field to which the application is being applied.
The data should be prepared so that relevant data points are maintained and that invalid or missing data is removed from the dataset. Once the data is prepared a machine learning algorithm can be selected for training.
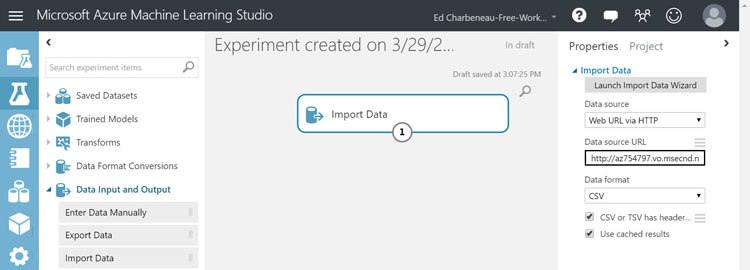
Import Data
Let's begin by importing data into the experiment. For the following examples we'll be using a dataset consisting of over 100,000 loan records. We'll be using the loan data to predict the delinquency of future loans.
To import the data we'll be using the Import Data module. The module will simply retrieve the data from the target data source and load it into the experiment. By setting the data source to Web URL via HTTP, the data will be loaded from the web. In this case, we'll select the CSV format and specify that the file has a header. Running the experiment will import the data. The CSV file, Loan Granting Binary Classification.csv can be found here.
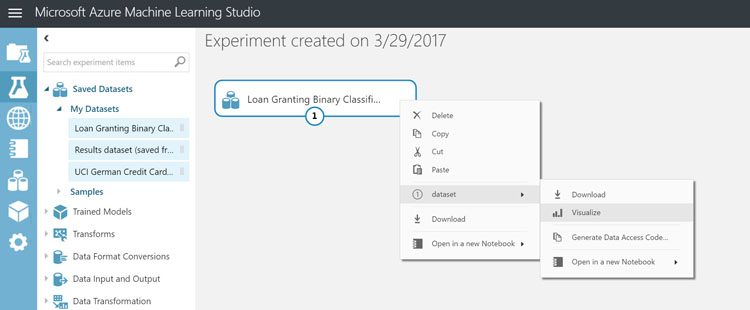
Loan Data Analysis
Let's analyze the data by right-clicking on the Import Data module and selecting Visualize from the menu. Right clicking on any module in the experiment will allow us to see the output from the module. For the Import Data module, we can visualize the data and understand various aspects of each data column such as: mean, median, min, max, and number of unique and missing values. Each data point also shows a histogram which can help us spot trend data and identify outliers.
Start by highlighting the Loan Stats column. This column identifies the loan as "Charged Off" and "Fully Paid". These values represent a binary outcome of the loan where "Charged Off" is the undesirable outcome, and "Fully Paid" is the desirable outcome. In banking these terms mean the bank charged off the loan and possibly lost revenue, or the loan was paid in full and the bank earned revenue. This column will eventually be the value we will attempt to predict.
We'll need to inspect the statistics of each column to identify problems so they can be cleaned from the dataset. In this dataset, we'll find the following problems:
- Credit Score: Items in the credit score columns have values that exceed normal credit ratings of 0-850. These values have an extra zero in the rightmost digit. For example the value is 7330, but should be 733.
- Current Loan Amount: Some values seem to be maxed out to 99999999 which is not a realistic loan value. These records will need to be cleaned.
- Home Ownership: Duplicate descriptions exist as HaveMortgage and Home Mortgage. These values can be combined as "Home Mortgage".
- Purpose: Duplicate descriptions exist as other and Other. These can be combined as "Other".
- Bankruptcies and Tax Liens: These columns have
NAstring values and should be converted to 0 allowing the column to be formatted as an integer. - Years in current job: This column contains 'n/a' values. These can be categorized with the existing '< 1 year' value.
Data Manipulation
To correct issues with our data we'll use a SQL query. There are other ways to manipulate data such as R scripts, and discrete data modification modules which we'll look at next. SQL is the most full-stack-developer-friendly option, so we'll start with that.
The following SQL script will correct the issues previously observed. In addition, the script will cast each value to it's appropriate data type.
SELECT
-- [Loan ID] not used
-- [Customer ID] not used
[Loan Status],
CAST(REPLACE([Current Loan Amount],'99999999',0) AS INT) AS [Loan Amount],
[Term],
CAST(SUBSTR([Credit Score],1,3) AS INT) AS [Credit Score] /* Clean outlier values of credit score */,
REPLACE([Years in current job],'n/a','< 1 year') AS [Years in Current Job] /* Clean n/a values in Years in current job */,
REPLACE([Home Ownership], 'HaveMortgage', 'Home Mortgage') AS [Home Ownership] /* combine home ownership: 'HaveMortgage' and 'Home Mortgage' */,
CAST([Annual Income] AS BIGINT) AS [Annual Income],
Replace([Purpose], 'other', 'Other') AS [Purpose] /* # combine Purpose: 'other' and 'Other' */,
CAST([Monthly Debt] AS FLOAT) AS [Monthly Debt],
CAST([Years of Credit History] AS FLOAT) AS [Years of Credit History],
CAST(REPLACE([Months since last delinquent],'NA','') AS INT) AS [Months Since Last Delinquent],
CAST([Number of Open Accounts] AS INT) AS [Number of Open Accounts],
CAST([Number of Credit Problems] AS INT) AS [Number of Credit Problems],
CAST([Current Credit Balance] AS BIGINT) AS [Current Credit Balance],
CAST([Maximum Open Credit] AS BIGINT) AS [Maximum Open Credit],
CAST(REPLACE([Bankruptcies],'NA','') AS INT) AS [Bankruptcies],
CAST(REPLACE([Tax Liens],'NA','') AS INT) AS [Tax Liens]
FROM t1;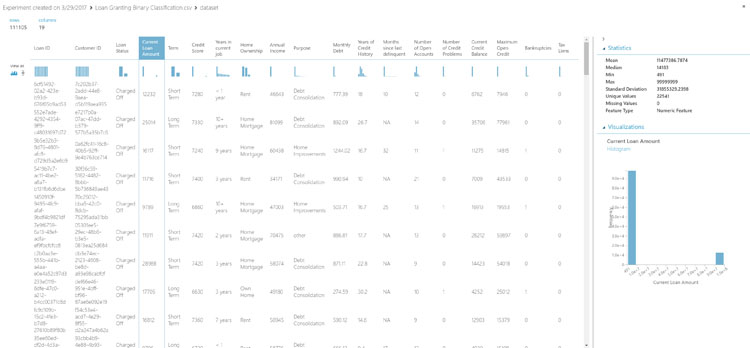
Missing Data
With the data transformed we still have some lingering issues with missing data. We'll address the missing data by either filling it, or removing the data from the set. To apply these transformations we'll use the "Convert to Dataset" and "Clean Missing Data" modules.
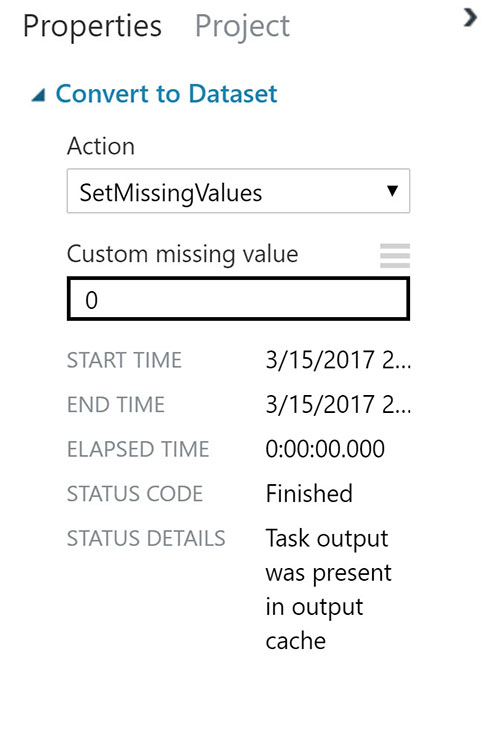
Let's start by filling missing values with the "Convert to Dataset" module by using the "SetMissingValues" action. This module will mark any missing values with a placeholder, in this case we'll replace 0.
Next, we'll clean up the missing values with the "Missing Data" module. The Missing Data module specifies how to handle the values missing from a dataset. We'll use several modules to tackle each scenario below:
-
Loan amount: Since a good amount of data exists in this column we can attempt to impute the data using a statistical algorithm. In this case we'll use the Missing Data module's "replace using MICE" cleaning mode. For each missing value, this option assigns a new value, which is calculated by using a method described in the statistical literature as Multivariate Imputation using Chained Equations or Multiple Imputation by Chained Equations.
-
Credit Score & Annual Income: In most instances, the credit score and annual income are both missing in the same row. It's best to simply remove these from the dataset completely. We'll apply the "remove entire row" cleaning mode for these items. As the name implies, rows with missing values in Credit Score and Annual Income will be removed.
-
All others: With the Loan Amount, Credit Score, and Annual Income missing values resolved, we'll set the any remaining data marked as missing to zero. Once again, we'll use the Missing Data module, and in this instance we'll use the "Custom substitution value" cleaning mode with the set value of
0.
We've learned a few of the basic modules for cleaning up data with Azure ML Studio, and there are even more modules we didn't cover. Cleaning data is an important step to understand in the process because the data is what we are relying for the basis of our model. Keep in mind that even if a perfect dataset is given during the Training phase of the experiment, that cleaning and data manipulation modules can be used on data received from a Web Endpoint as well for filtering data coming from a user or application.
Building a Model
The result of training a machine learning algorithm against data is a model. In order to produce a model we'll need to create two sets of prepared data, a training data and test data. This allows the model to be trained and validated against the test data. This process produces a score which will help determine the model's accuracy. The desired accuracy of the model depends on the application and how it is utilized.
Training a model is similar in some respects to creating a unit test in computer programming, in that a model is validated against known test data. However, instead of asserting a simple pass or fail result, a probability between 0 and 1 is returned. A scoring model assesses the many results of the test data and provides additional metrics of the models accuracy.
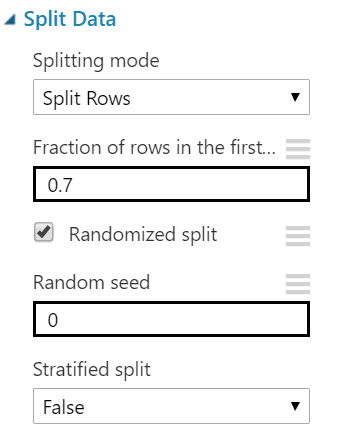
Let's split our data using the Azure ML "Split Data" module. This module will help divide our data into training and test data. Using the "Fraction of rows in the first output dataset" option, we can decide how much of the data to dedicate to either training or testing. In our case we'll set the value to 0.7 lending 70% of the data to training.
Choosing Algorithms
Azure ML has a large library of algorithms from the regression, classification, clustering, and anomaly detection families. Each is designed to address a specific type of machine learning problem. To assist with this process Microsoft has provided a cheat sheet helps you choose the best Azure ML algorithm for your predictive analytics solution. The algorithm you choose is largely decided by the nature of your data and the question you’re trying to answer.
For our loan approval data we'll use a Two-Class Boosted Decision Tree module. Boosted decision trees are good general purpose machine learning algorithms and will work well for our dataset. It's worth noting that decision trees are memory-intensive learners and may not be able to process very large datasets.
We'll add a "Train Model" module to the experiment by connecting the first output of from the "Split Data" module to the second input of the Train Module. Next, we'll need to identify the label column, this is the column that contains the outcome that we would like to train the model to predict. For our loan data, this is the Loan Status.
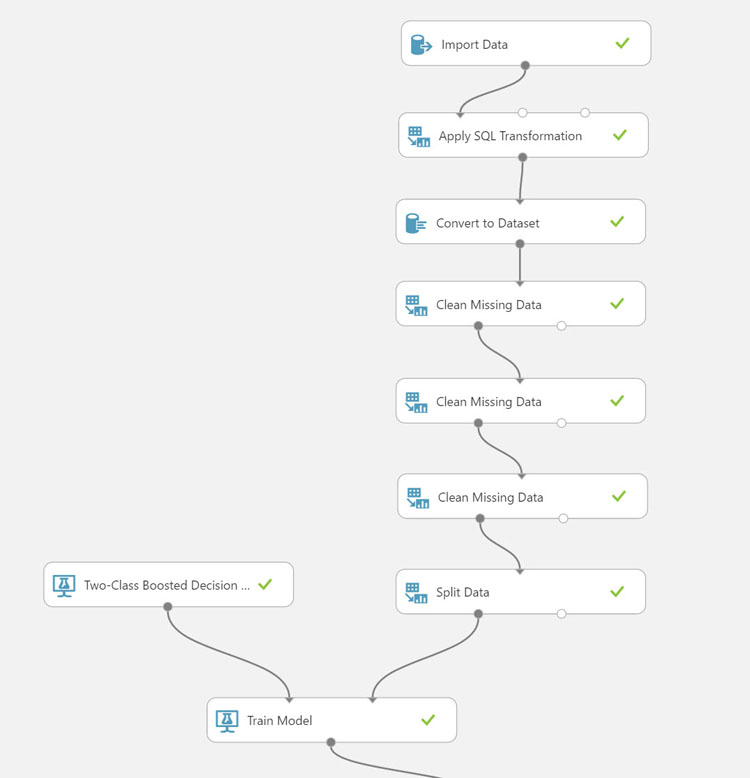
To utilize the "Two-Class Boosted Decision Tree" we'll add the module and connect its output to the first input of the Train Model module. This completes the training portion of the model, next we'll need to score and evaluate the model.
Scoring and Iteration
To complete the training experiment we'll need to score our model. Once the first model is created, the score will determine the models effectiveness and may reveal problems that need to be addressed. It's possible that missing or invalid data points will reveal themselves through scores that are on the extreme ends of the accuracy spectrum. Even scores that look normal may benefit from additional refinement to increase its accuracy. Experimenting with your model using different parameters and working through problems with data is part of the process of finding the right model.
Let's add a "Score Model" module to the experiment. We'll direct the output from our trained model to the first input, and the validation data from the "Split Data" module to the second input. This will create a scored data set that contains a column of scored probabilities.
The scored probabilities show the probability that the corresponding entry falls into a the Charged Off or Fully Paid class. If the scored probability of an input is larger than 0.5, it is predicted as Fully Paid. Otherwise, it is predicted as Charged Off. To see these results we can right-click on the module and select Visualize from the menu.
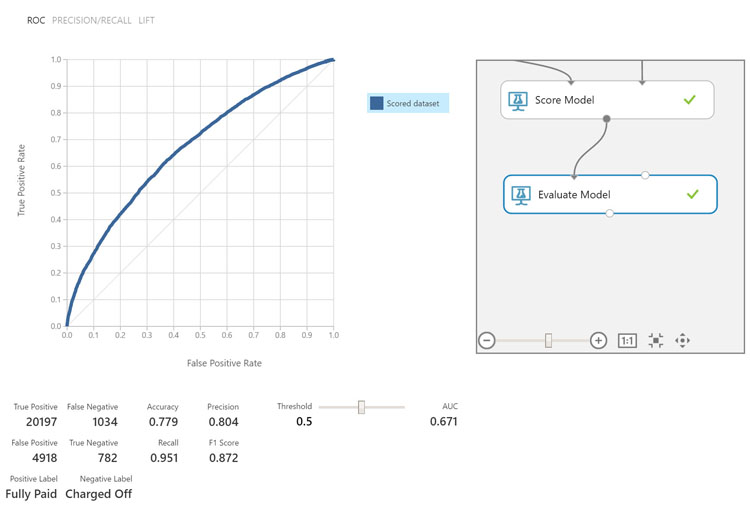
Finally, we'll evaluate the model with the "Evaluate Model" module. This module will provide a statistical analysis of how the model performed. The evaluation metrics available for binary classification models are: Accuracy, Precision, Recall, F1 Score, and AUC. In addition, the module outputs a confusion matrix showing the number of true positives, false negatives, false positives, and true negatives, as well as ROC, Precision/Recall, and Lift curves.
Once the Evaluate Model module is connected to the output of the Score Model module, run the experiment and visualize the output from the Evaluate Model module.
For the scope of this article we'll be looking at the Accuracy and Area Under the Curve (AUC) to understand the effectiveness of our model. The evaluation shows that the Accuracy of the model is 0.779 or 77.9%. Determining if an accuracy is adequate for your model depends on your business needs. For example, our model determines if a customer is per-qualified for a loan from a bank. An accuracy score of 79% may be fine for this scenario, however if your model were predicting a if a medication will be effective in a patient, then the accuracy may need to be higher.
Next we'll look at the AUC. The AUC corresponds to Receiver Operating Characteristic (ROC) curve which includes the true positive rate versus the false positive rate. The closer this curve is to the upper left corner, the better the classifier’s performance is, this means we have a higher true positive rate and lower false positive rate.
If we determined the score is insufficient for our needs, we iterate through the process of cleaning data, tuning or choosing alternative learning algorithms and comparing the scores of previous models. For our scenario we'll consider the process complete. Our model is capable of taking various factors of customer loan data and provide a reasonable prediction on the risk of lending money to an individual. With the model complete we can continue the process by setting up a web service to enable applications to utilize the predictive model.
Next Steps
Throughout this example we learned how to build a Training Experiment by exploring the basics of Azure ML studio. By using modules within Azure ML we cleaned data, trained and evaluated a machine learning model, and predicted loan behavior based on the data provided.
In the next article we'll learn how to use a Predictive Experiment to create a Web API endpoint for consuming the machine learning model. We'll look at the process and identify key points of interest for developers so they can help shape the API created within Azure ML.
Header image courtesy of Neil Conway

Ed Charbeneau
Ed