
Building Predictive Web Services

Summarize with AI:
An Azure predictive web service uses the power of Machine Learning (ML) to deliver a prediction based on a set of input data. In this article we’ll learn about building a predictive web service using Azure ML Studio. We’ll continue to use a training experiment created in the previous article Machine Learning for Developers as an example in this process. The training experiment can be created using the article Machine Learning for Developers as a guide, or you can jump right in by creating a copy of the training experiment from the Cortana Intelligence Library.
A training experiment utilizes training data, validation data, and machine learning algorithms to build a trained ML model. In this training experiment, loan history is used to create a trained model which can predict a loan’s status of Fully Paid or Charged Off based on a set of criteria. We’ll use this prediction to determine if an individual is pre-approved for a loan.
Currently, the training experiment can successfully predict loan status. However, the training experiment cannot process predictions on new data or be of use outside of Azure ML Studio. Making practical use of the experiment in a software application will require additional steps. The training experiment must be converted into a Predictive Experiment and web service.
Converting to a Predictive Experiment
The purpose of the predictive experiment is to use your trained model to score new data. The final step will be to deploy the predictive experiment as Azure Web service.
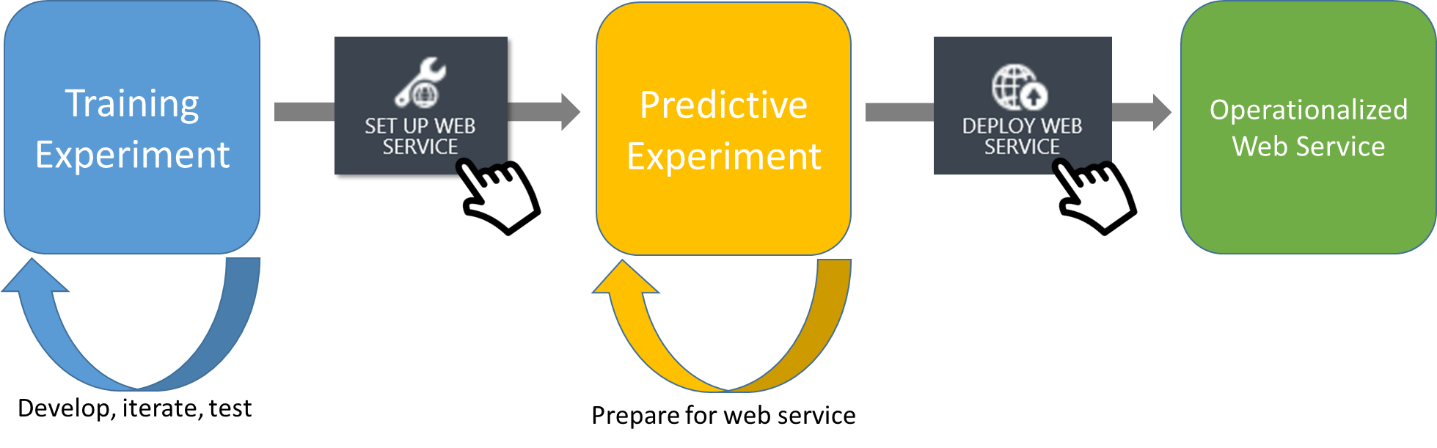
The process of converting from a training experiment to a predictive experiment is a one-click process. When preparing to convert to a predictive experiment, the training experiment should be production ready. Once the conversion takes place the predictive experiment becomes independent of the training experiment. Further changes to the training experiment will not automatically update in the predictive experiment. Updates can be performed through the tooling, however breaking changes can occur in the predictive experiment.
To start the process we’ll click “set up web service” from the Azure ML menu. This process will convert the set of modules used for training into a single trained model module. Modules that are not related to scoring will be removed, and web services endpoints will be added.
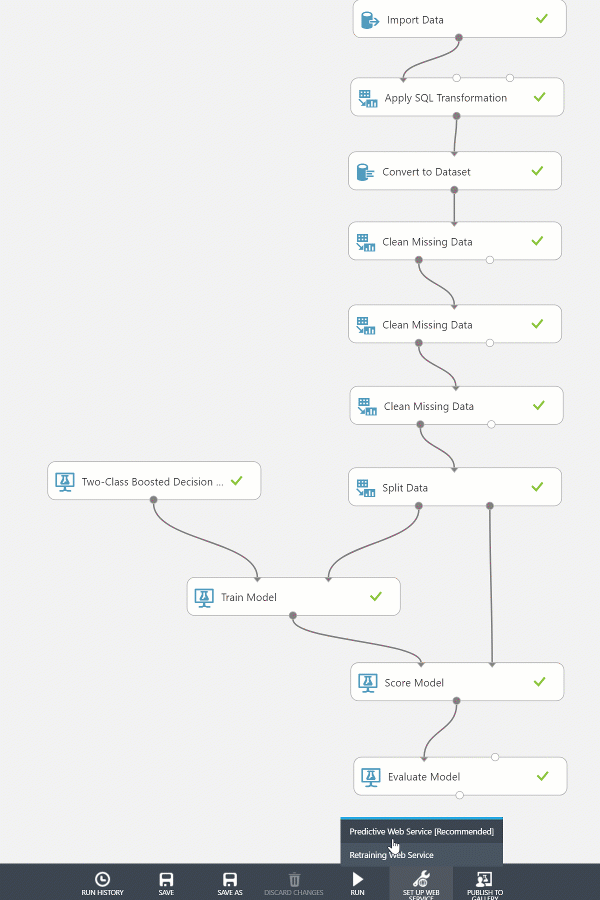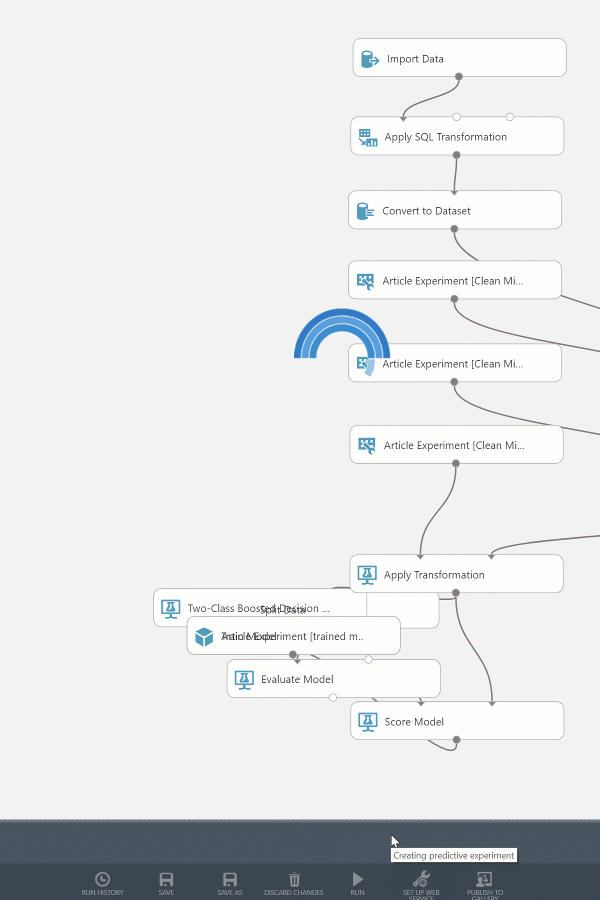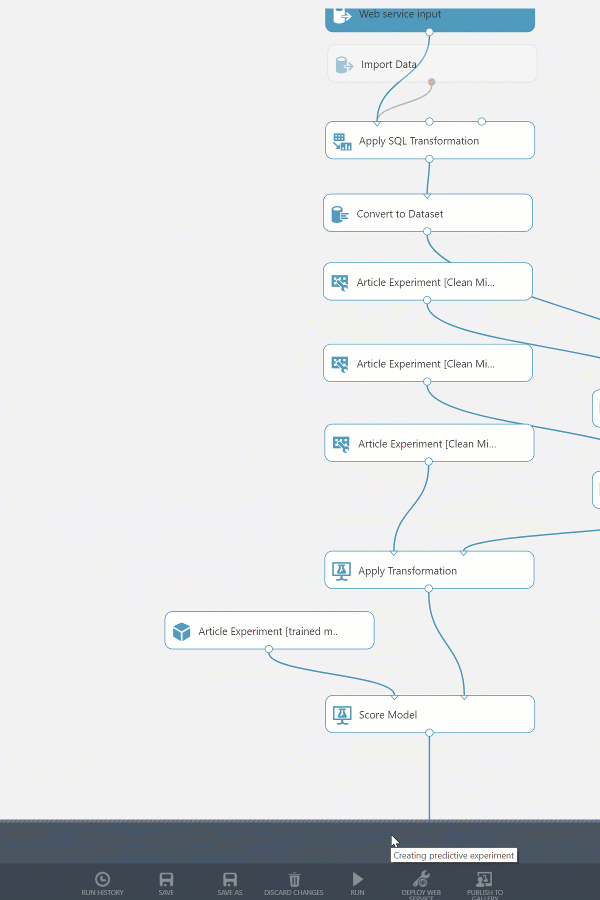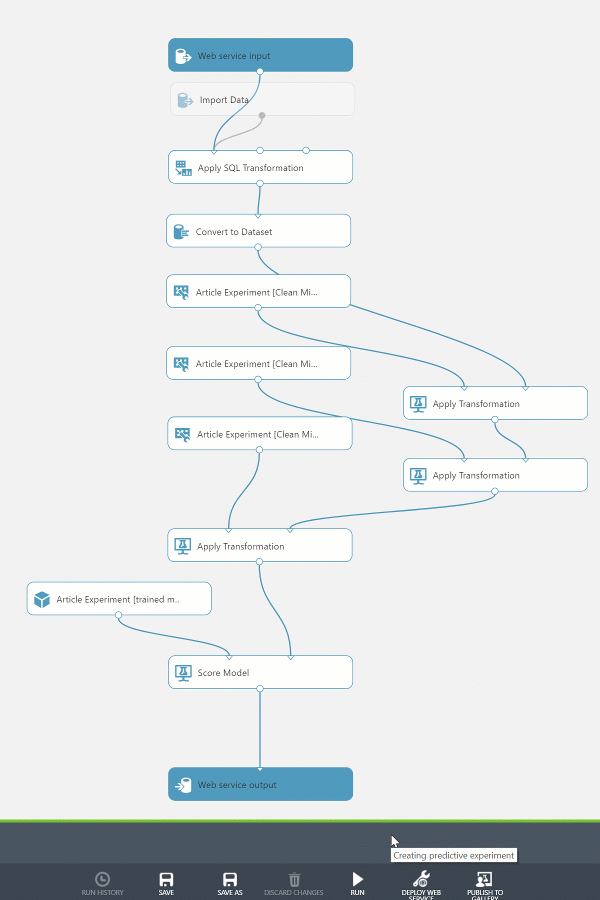
Preparing the Web Service
By default the predictive web service has two web service modules attached, an input and output. The Web Service input and Web Service output modules will work out-of-the-box, however some fine tuning will help ensure that the web service is easily consumed. We’ll remove any unused input parameters, configure the output produced, and name the endpoints appropriately.
If we used the web service as-is it would contain many unused input & output fields.
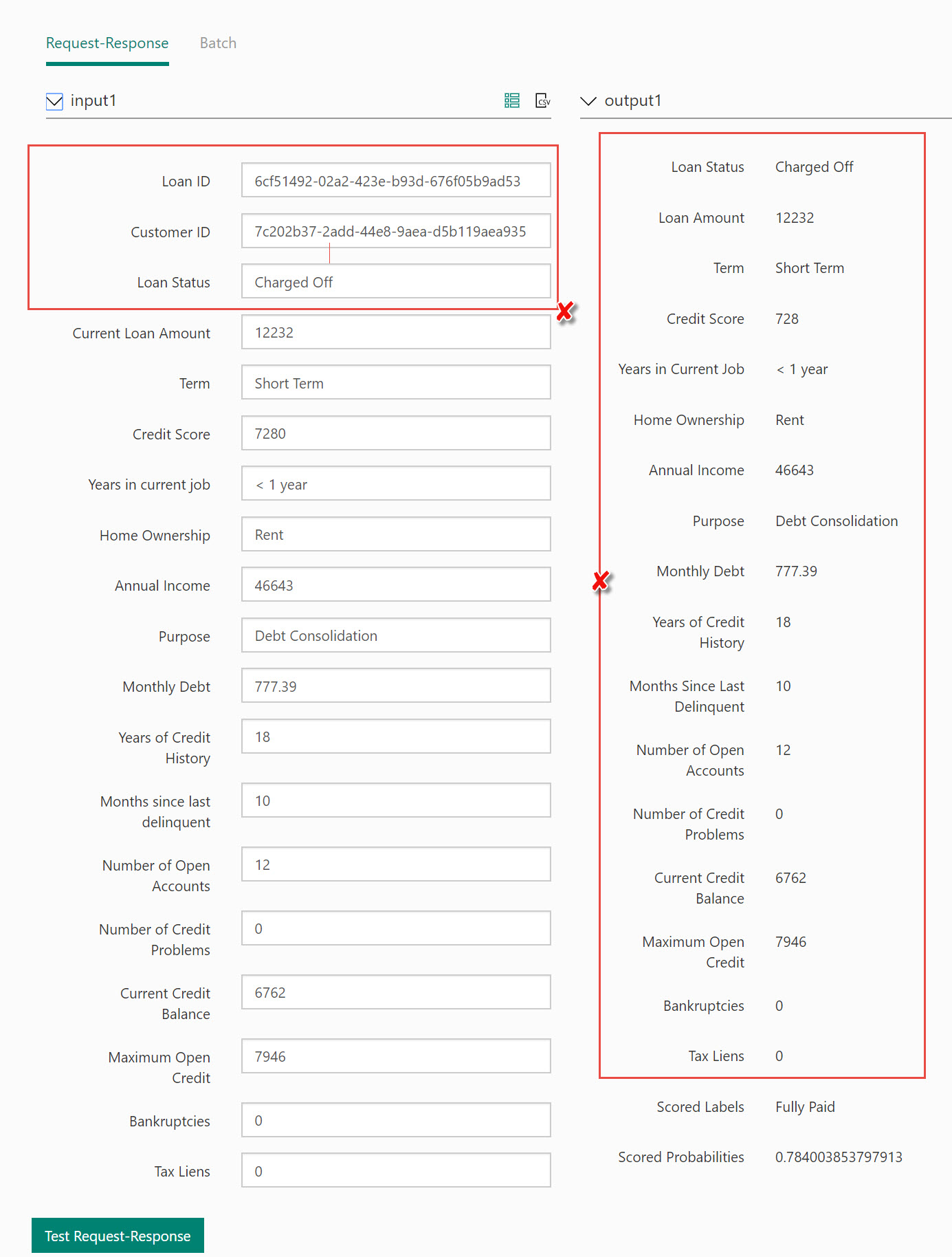
Input Parameters
The Web service input module named “input1” is attached immediately after the Import Data module. Because “input1” is tied to directly to the results of the import data module it will include all of the data points from the result set. This means the web service parameters will include the unused data points Loan ID and Customer ID. In addition, the web service parameters will all be configured to string data types because the transformations provided by the preceding module have not taken place. If no changes are made to the module, these issues will impact the web service and potential application logic further in the process.
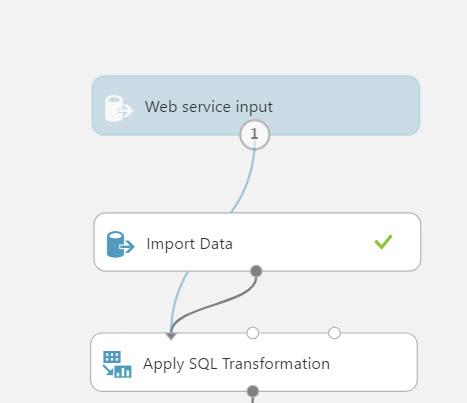
Let’s make a simple change to resolve the issue by moving the connector for “input1” to the input of the Score Model module.
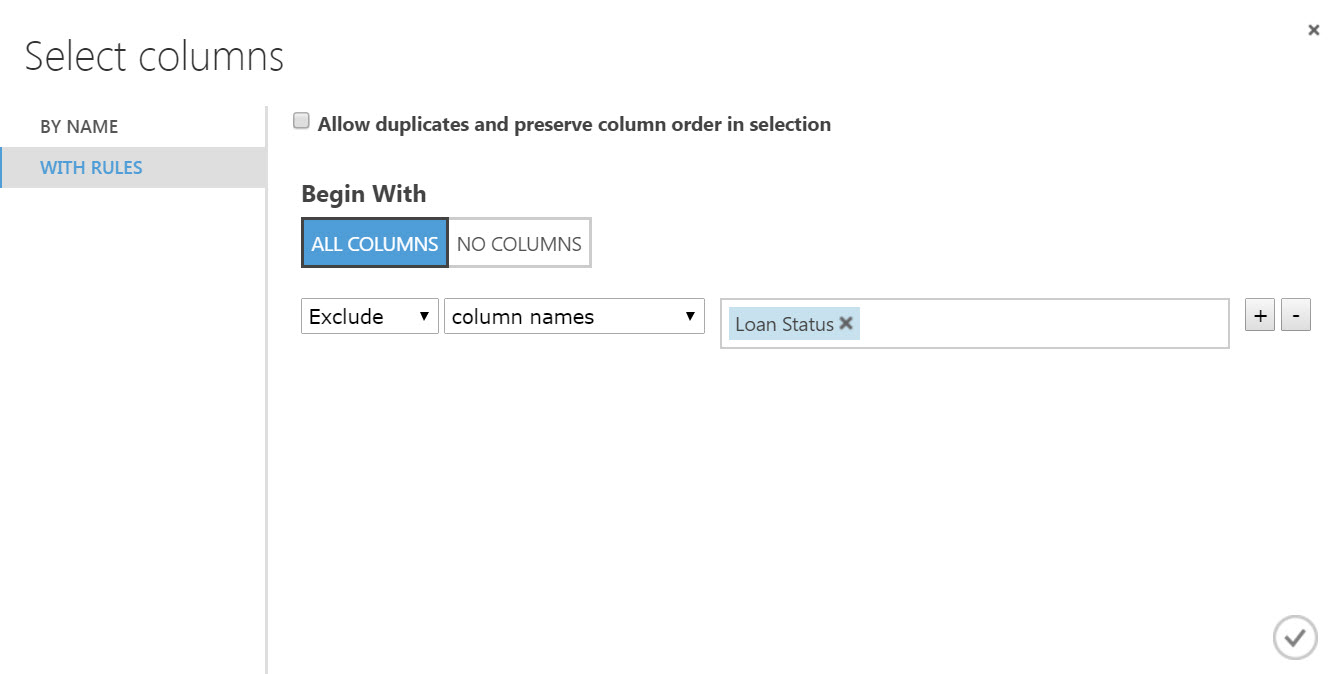
The Loan Status data point, used in the training experiment as the label column exists in the predictive experiment. While the Loan Status in the value is required for training, it’s no longer needed in the predictive experiment since this is the value the model produces as a prediction. If the data point remains in the experiment as an input it will become an unused parameter of the web service. To remove the Loan Status data point we’ll use a Select Columns in Dataset module and exclude the Loan Status column.
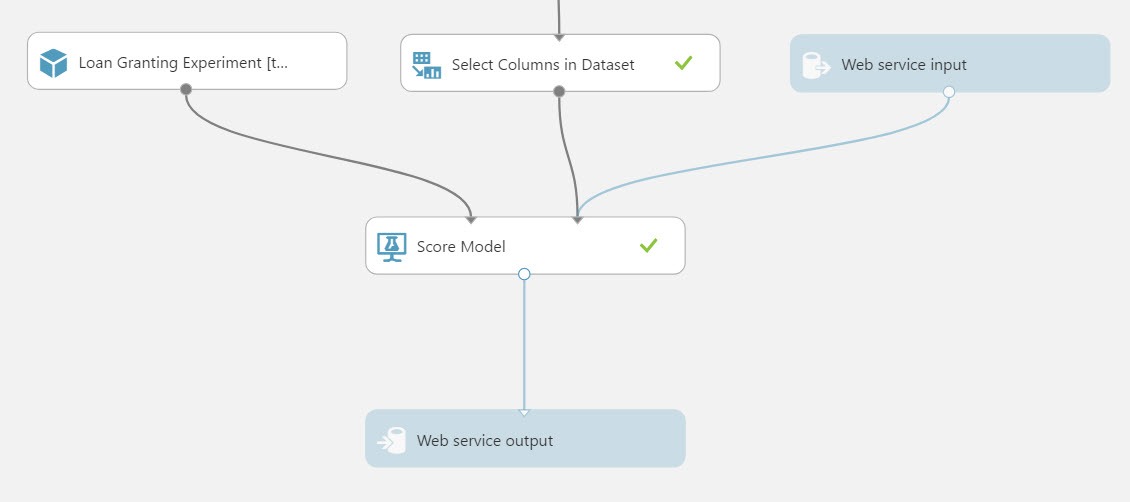
Let’s delete the connection leading into the Score Model module and insert a Select Columns in Dataset module, set the module to exclude the Loan Status column.
This modification completes the preparation of the Web Service input. Let’s name the Web Service input to identify its usage. A proper name will also help developers when consuming the service from a typed language like C# as the name can be parsed to a strongly typed object. Choose the Web Service input module, and change the name property from “input1” to “CreditProfile”.
Output Results
The Web service output module named “output1” is attached after the Score Model module. In this configuration the output response of the web service will contain the Scored Probabilities, the Scored Labels, and all of the data points used for scoring, 18 in total. Since the data is not changed in the prediction process returning all data is unnecessary and the output should only contain the Scored Probabilities and Scored Labels. Let’s modify the Scoring Model module to only output what’s needed.
Choose the Scoring Model and uncheck Append score columns to output. This simple modification will reduce the number of data points returned from 18 to 2.
Our web service will return a Scored Label of “Charged Off” or “Fully Paid”. Let’s return something a little more developer friendly and easily consumed by an application. A Boolean value identifying approval or disapproval is the ideal response for this experiment. Let’s change the output values of “Charged Off” to “false” and “Fully Paid” to “true”.
Delete the connection from Scored Model to Web Service output. In between these modules add two Convert to Dataset modules. Reconnect the Scored Module and Convert to Dataset modules in series, leave the Web Service output disconnected for the moment.
Select the first Convert Dataset module and set following properties:
- Action: ReplaceValues
- Replace: Custom
- Custom Value: Fully Paid
- New Value: true
Select the second Convert Dataset module and set following properties:
- Action: ReplaceValues
- Replace: Custom
- Custom Value: Charged Off
- New Value: false
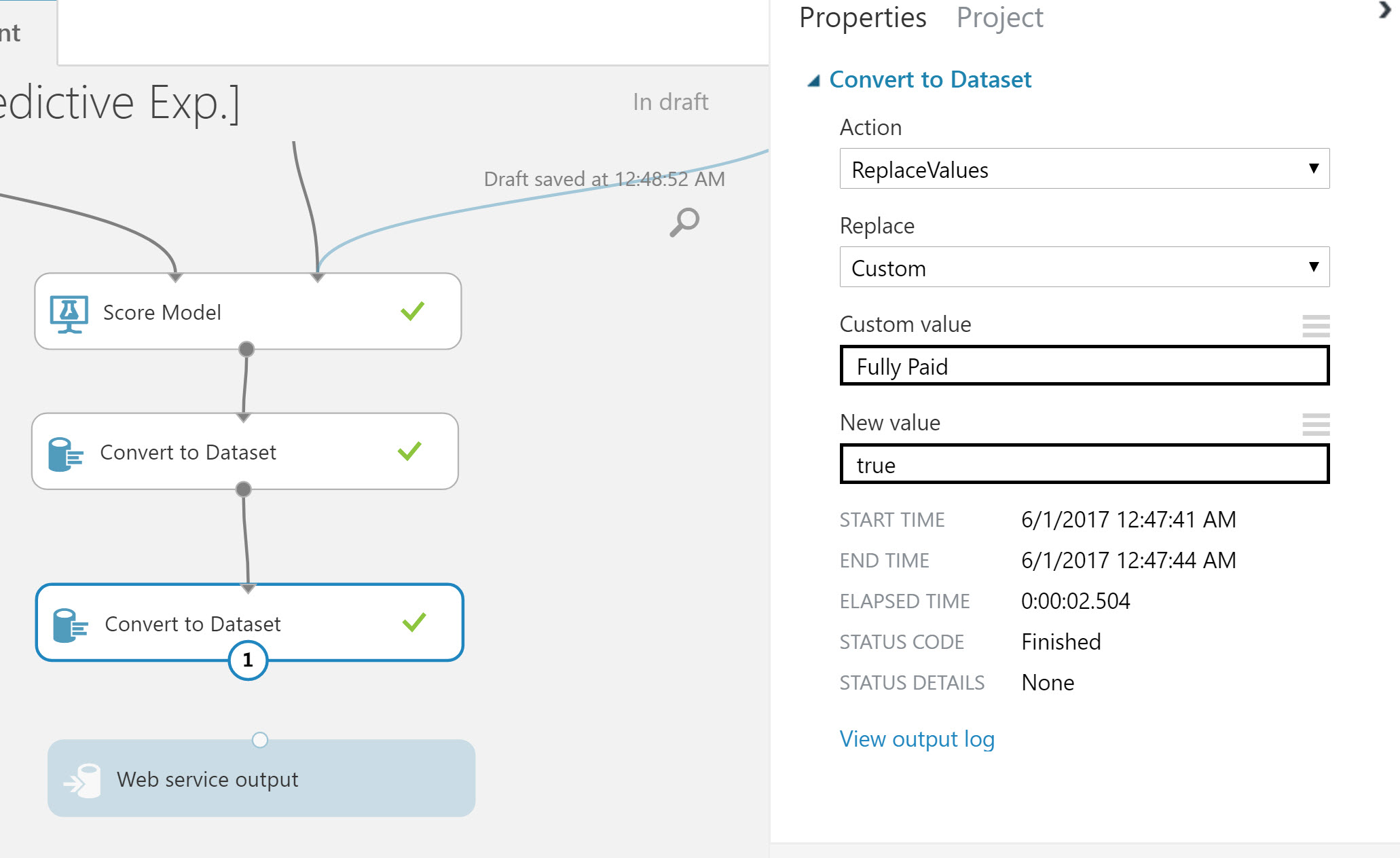
It’s important to return lower cased “true” and “false” values from the web service. The web service output will be serialized as JSON and lowercase is a valid JSON Boolean value. At the time of writing, Azure ML converts its internal Boolean data type to a Pascal case value (“True/False”), thus causing parsing errors due to invalid JSON data. By using the Convert Dataset module and setting the values explicitly we avoid this issue.
With the values converted we’ll focus on naming the output value appropriately. Let’s change the name Scored Label to IsApproved. We’ll do this by connecting an Edit Metadata module to the last Convert Dataset module. This will be the final module added to the experiment so we can reconnect the Web Service output to the result of the Edit Metadata module.
Choose the Metadata module and set its properties to:
- Selected Columns: Scored Label, Scored Probabilities
- DataType, Categorical, Fields: Unchanged
- New Colums Names: IsApproved, Scored Probabilities
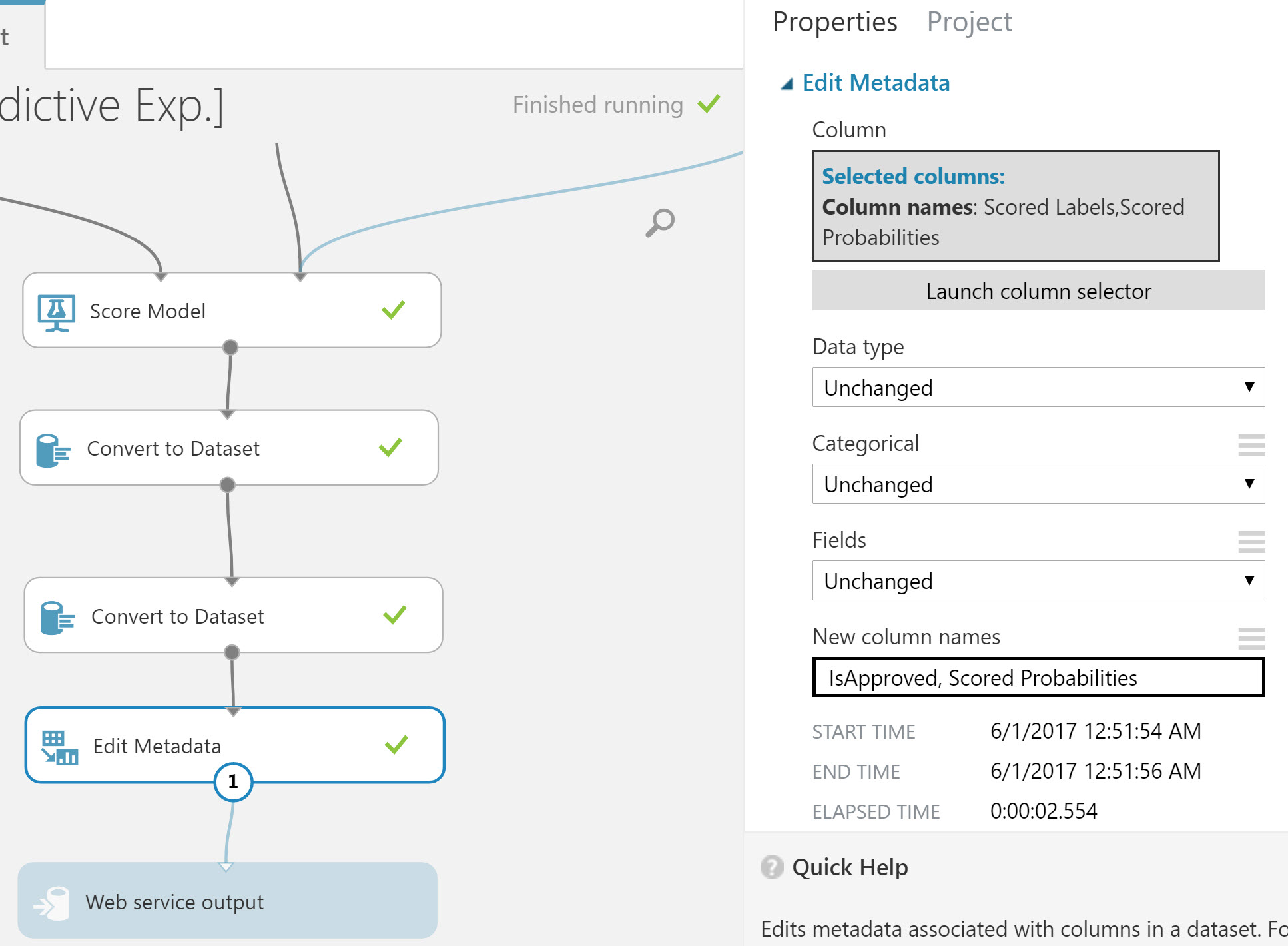
This modification completes the preparation of the Web Service output. Let’s name the Web Service output to identify its usage. Choose the Web Service output module, and change the name property from “output1” to “ApprovalStatus”.
The result of these changes will provide a JSON response of: { "IsApproved": true, "Scored Probabilities": o.83 }
With the web service prepared we can focus on deploying and testing the web service. Deploying the web service is the final step in the experiment process.
Deploying and Testing
Much like the converting from a Training Experiment to a Predictive Experiment, deploying a web service is a one-click process. Since we took care of our prep work ahead of time, the web service will have only the necessary inputs and outputs. In addition, the request/response values will be named appropriately. If any preparation steps were missed, then further changes can be made to the web service. The only caveat is that republishing the web service could affect users already consuming the service. Thankfully there are tools included to help test the web service and make adjustments.
Before publishing, double check the Web Service input/output name properties, some edits can cause the values to revert back to “input1/output1”. To publish the web service, click Deploy Web Service from the bottom tool bar. After clicking deploy Azure ML Studio will automatically open the Web Service Manager dashboard where we can begin testing the web service.

From the Default Endpoint section, click Test (preview) to open the testing window. Once the testing window opens, choose to Enable Test Data. Enabling test data will populate the input fields on the test page.
Clicking, Test Request-Response will exercise your predictive model via the web service.
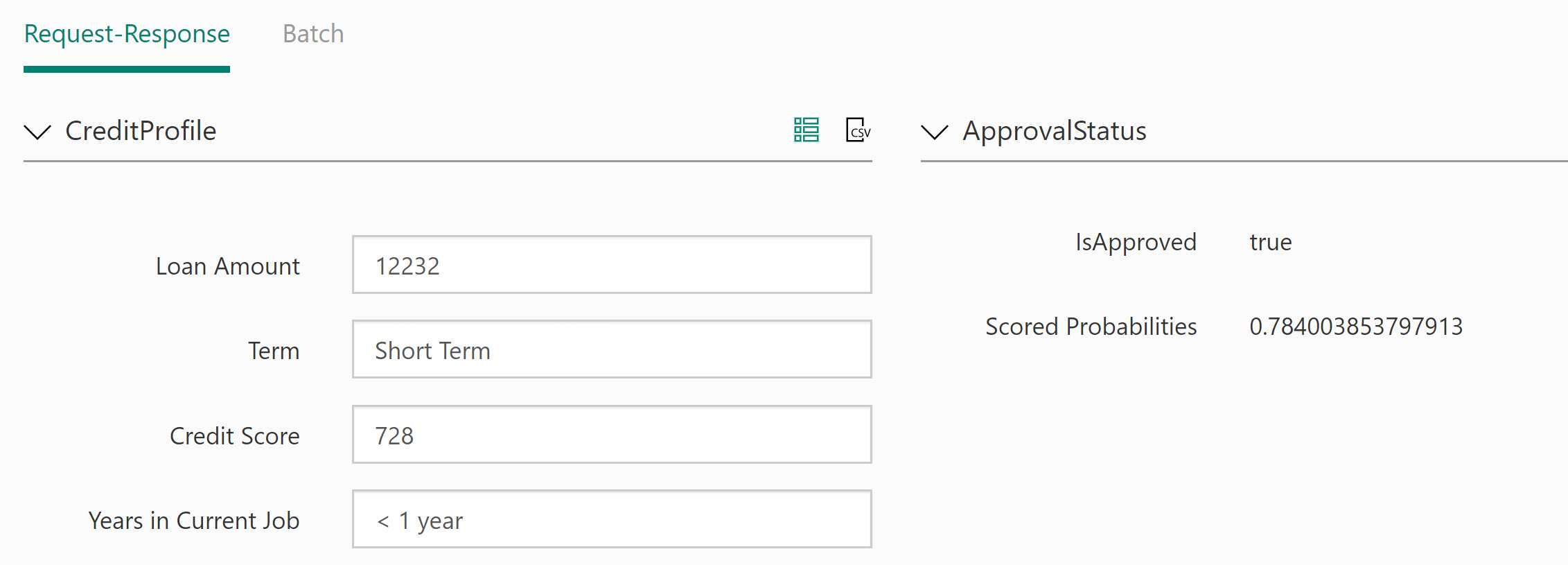
Once we’re satisfied with the web service, it can be consumed from any application that can communicate using JSON over HTTP request.
Next Steps
Throughout this example we learned how to build a Predictive Experiment by exploring the basics of Azure ML studio. By using the convert to web service function within Azure ML we converted our training experiment to a predictive experiment. We prepared our predictive experiment to streamline the web service generated by the Deploy Web service process, and tested the behavior in the Web Service Manager.
In the next article we’ll learn how to consume the Web Service we created. We’ll look at the process and identify key points of interest for developers so they can help shape the API created within Azure ML.

Ed Charbeneau
Ed