
A Case Study in JavaScript Code Improvement

Summarize with AI:
Hi, I'm Raymond, and I write a lot of bad code. Ok, not bad, but I don't necessarily always follow "best practices." I'm willing to bet a lot of the people reading this article don't necessarily also follow those same best practices. In this post, I am going to discuss how a recent project caused me to use a number of simple tools that, in the end, helped me write code that I can be proud of. To explain, let me share the story.
The Backstory
Over the holiday break I did my best to not even look at my laptop, but I failed pretty horribly.
I was happily preparing myself for a round of video game playing (sorry, hand-eye coordination training) when someone shared a bit of exciting news with me - the release of a Star Wars API. While not "official," this simple REST-based API provided a way to fetch content for characters, films, starships, vehicles, species, and planets. The Star Wars API is a free service with no authentication requirements. It doesn't provide any search capabilities yet, but for a free service, it's nice. And, if you know me, I'm into anything Star Wars related.
On a whim, I wrote a super quick JavaScript library to integrate with the API. At the simplest level, you can fetch all of one type of a resource:
//get all starships
swapiModule.getStarships(function(data) {
console.log("Result of getStarships", data);
});Or fetch one particular item:
//get one starship (assumes 2 works)
swapiModule.getStarship(2,function(data) {
console.log("Result of getStarship/2", data);
});The actual wrapper code is one JavaScript file. I wrote it along with a corresponding test.html file, and dropped it up on GitHub: https://github.com/cfjedimaster/SWAPI-Wrapper/tree/v1.0. (Note, this is a link to the original version of the project, you can access the final project here.)
It was a fun way to waste an hour and frankly, every bit of JavaScript I write makes me feel like I'm (slowly) improving my craft.
But then it began. That... little nagging in the back of my head. Couldn't I write some of this code better? I should have unit tests, right? Why don't I add a minified version too? These are all things that I knew weren't required per se, but I felt guilty that I wasn't doing the best job I could. (Not guilty enough to immediately return to the code. It is the holidays after all!)
As it gnawed on me over the next few days, I began to mentally consilidate the things I'd do to improve the project and make it a bit more aligned with developer best practices. Obviously this list may not match your list, but they do represent good improvements I can make to the project.
- While writing the JavaScript, I ran into a few bits of code that felt repetitive and seemed ripe for optimization. I intentionally ignored those thoughts and focused on getting the code working. Premature optimization is frowned upon for a reason. Now that the code is released though, I think it makes sense to go back through and look for improvements to the code base.
- Obviously - and probably more sensible before the optimization, would be the use of unit tests. As this relies upon a remote service, writing tests could be problematic, but even a test that assumes that remote service is running perfectly would be better than no tests. Plus, if I write these tests first, I can then look into code changes and feel secure that I've not broken anything.
- I'm a big fan of JSHint and would like to run it over the code base and make sure it passes that test as well.
- I'd also like to ship a minified version of the library. To be honest, I've never done that before, but if I had to guess, I'd bet there is a command line program I could run to generate that.
- Finally, I bet I can handle running the unit tests, JSHint checking, and the minification, automatically via a tool like Grunt or Gulp.
In the end I'll have a project that I can be more confident in. I'll have a project that is better for my end users. I'll move the project from something that looks like Jar Jar wrote it to something that is a bit more Jedi like. In this article I'm going to go over each of these steps and describe how I implemented them for my project. Since the first item is the most vague and open ended, I'll discuss it last.
Adding Unit Tests
I'm assuming now that it is 2015 we all know what unit tests are. If by some wild chance you don't, then the simplest way to think of them as a set of tests that ensure the various aspects of your code work correctly. Imagine a library with two functions: getPeople and getPerson. You could have two tests - one for each. Now imagine getPeople allowed you to optionally search. You should write a third test to ensure searching works. If getPeople also let you paginate and specify a starting point for returning results, then you would need even more tests to cover those options. You get the idea. The more you test the more sure you can be sure your code is working correctly.
My library has 3 unique types of calls. The first call is getResources. This simply returns a list of the other API end points. This isn't necessarily something I see end users actually using but I supported it for completeness sake. Then we have the abilities to get one unique item and get all items. So for planets we have getPlanet and getPlanets. But that's not all. The calls that return everything actually returned paged data. So my API supports calling getPlanets as well as getPlanets(n) where n represents a particular page of data. This means we have 4 types of things we need to test:
- The
getResourcescall. - The
getSingularcall for each resource. - The
getPluralcall for each resource. - The
getPluralbut a particular page for each resource.
Since we have one general method and three per resource, that means 1 + (3 * the number of resources) tests. Since there are 6 types of resources, I'll need 19 tests. That isn't too bad. One of my favorite libraries, Moment.js, has 43,399 tests.
For my unit tests I decided to use Jasmine. Jasmine has a syntax that feels nice to me and it's the JavaScript unit test framework I'm most familiar with.
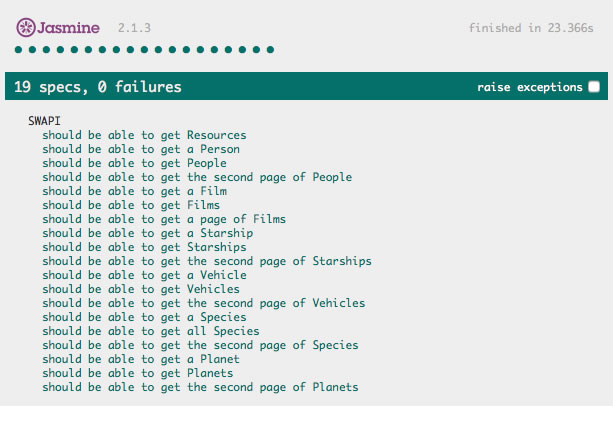
One of the things I like about Jasmine is that it includes a "spec runner" and sample test you can quickly modify and start hacking away at. The spec runner is simply an HTML file that includes your library and your tests. When opened, it runs them and displays the results in a nice summary. I began by writing a unit test for getResources. Even if you've never seen Jasmine before, I'm betting you can understand what's happening here:
it("should be able to get Resources", function(done) {
swapiModule.getResources(function(data) {
expect(data.films).toBeDefined();
expect(data.people).toBeDefined();
expect(data.planets).toBeDefined();
expect(data.species).toBeDefined();
expect(data.starships).toBeDefined();
expect(data.vehicles).toBeDefined();
done();
});
});The getResources method returns a simple object with a set of keys representing each resource supported by the API. Therefore I can simply use toBeDefined as a way of saying, "I expect this key to exist." The done() at the end of my test is how Jasmine handles testing asynchronous calls. Now let's consider the three other types of calls. First, getting one object of a resource.
it("should be able to get a Person", function(done) {
swapiModule.getPerson(2,function(person) {
var keys = ["birth_year", "created", "edited", "eye_color", "films",
"gender", "hair_color", "height", "homeworld", "mass", "name",
"skin_color", "species", "starships", "url", "vehicles"];
for(var i=0, len=keys.length; i<len; i++) {
expect(person[keys[i]]).toBeDefined();
}
done();
});
});My first test checks getPerson. As you can guess, this gets one person from the Star Wars universe. Like getResources this just returns an object. In order to save me some typing, I created an array of keys that I can loop over and use toBeDefined(). Theres some problems with this test. I'm assuming there is a person with the ID of 2. I'm also assuming that the keys that represent a person aren't going to change. I'm ok with this. I expect the data returned from the API to be pretty consistent. If it does change in the future and I need to update my test, it will be pretty simple to do so. Also, the principal of "premature optimization" can certainly be applied to my tests as well. This is my draft of unit tests and I can definitely come back later to make them more intelligent. Now let's look at the call to get all people.
it("should be able to get People", function(done) {
swapiModule.getPeople(function(people) {
var keys = ["count", "next", "previous", "results"];
for(var i=0, len=keys.length; i<len; i++) {
expect(people[keys[i]]).toBeDefined();
}
done();
});
});This is pretty similar to the getPerson call with the main difference being in the keys returned. Next lets test getting the second page.
it("should be able to get the second page of People", function(done) {
swapiModule.getPeople(2, function(people) {
var keys = ["count", "next", "previous", "results"];
for(var i=0, len=keys.length; i<len; i++) {
expect(people[keys[i]]).toBeDefined();
}
expect(people.previous).toMatch("page=1");
done();
});
});This is fairly similar to the previous test with a small addition of ensuring that it has a link to the previous page. Again, I think there are some improvements that could be made here. Do I really need to check the keys of the object in the "page" test? Maybe not. But I'm going to leave it for now.
That's pretty much it. I then simply repeat these three calls for my other 5 types of resources. As I wrote my tests, I discovered some interesting problems with my code, which is just one more reason why writing tests can be so helpful. getFilms, for example, only returns one page of films, and I discovered that I didn't adequately handle error conditions in my API. How exactly should getFilms(2) respond? With an object? A JavaScript exception? I don't know yet but it is something I'll have to handle eventually (I decided to put it off until the next major revision). Once my tests were done, I could then run the web page and ensure everything was passing.
Linting your code with JSHint
Next on my list of improvements was to make use of a linter. A linter is simply a "code quality" tool that scans your code for issues. These issues may be bugs, performance improvements, or simply code that doesn't match best practices. The original JavaScript code linter is JSLint, but I use an alternative called JSHint. JSHint is a bit more relaxed than JSLint, and as I'm a relaxed kind of guy, it feels like a better fit for me.
There are multiple ways to use JSHint, including in your favorite editor. I use Brackets (currently my favorite editor) and there is an extension to provide JSHint support directly in the editor. I can see issues as I type. But for this article I'll use the command line version. As long as you've got npm installed you can simply npm install -g jshint to add a JSHint CLI program for your environment.
Once you've done that, you can then run the linter against your code. As an example:
jshint swapi.jsAfter I did exactly that, I then spent ten minutes researching the command line arguments when nothing was reported. Turns out, my simple little library actually passes the default set of options for JSHint. Yes, it passed. I'm still shocked. The CLI doesn't actually say it passed though, which in my opinion is a mistake, but for now, no news, or output, is good news.
Just to be sure, I intentionally added some junk to my file.
var swapiModule = function () {
var rootURL = "http://swapi.co/api/";
y=1
<bold>I've included both a line that doesn't use semicolons (the horror!) as well as raw HTML. JSHint will notice, and flag, raw syntax errors as well. Here's the output from the CLI:
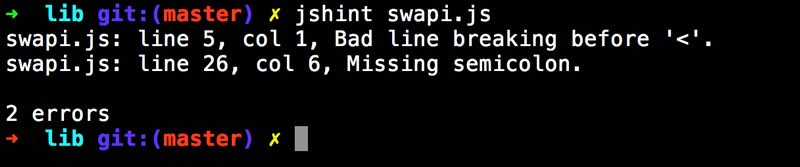
Make note of the line numbers in the screenshot above. The issues are correct, and the first line reported is right, but the second is completely wrong. My guess is that JSHint gets confused by the raw HTML in the file. Since that is probably not something even a beginner would do, it isn't something that concerns me. If you remove the html tag, you still get the error about the semicolon and it reports the right line. And in case your curious, JSHint supports a wide array of options, including the option to suppress messages about semicolons. But remember that every time you leave off a semicolon, God kills a kitten. Seriously (I read about it on the Internet).
Minifying the Library
The next improvement we'll make it to minify the library. It isn't a huge library now (128 lines), but I don't expect it to shrink over time and frankly, if it's easy to minify the code there isn't really a reason not to. Minification typically involves stripping out the whitespace, reducing variable names, and making the file as small as possible. I selected UglifyJS to handle the task. Once installed, I can then simply do:
uglifyjs swapi.js -c -m -o swapi.min.jsYou can check the docs for a full explanation of the arguments, but I basically asked the tool to minify the code by shortening variable names as well as removing white space. What's cool is that when I ran this, it actually noticed something I had forgotten:
//generic for ALL calls, todo, why optimize now!
function getResource(u, cb) {
}This function is pretty harmless as is, but it is a waste of space, and uglify noticed it right away:

The final result? My original file was 2750 bytes big. The minified file is 1397. That's about a 50% reduction in the file size. Obivously 2.7K is pretty darn small, but the point is, as my library grows, I can use this tool to ensure I provide a slimmer option.
Automate This Stuff!
Ok, so far so good. I've got unit tests to ensure my library works. I've got a code quality checker as well. Finally, I've got a tool to minify the code. While all of this is relative easy to do, I'm a pretty lazy person. What I really want is to automate the entire thing. In my mind, the perfect process would be:
- Run the unit tests, and if they pass...
- Run the JSHint test, and if it passes...
- Generate a minified version of the library.
To make this happen, I'm going to use Grunt. This isn't the only task runner for web development, but, as I haven't used Gulp yet, my default is Grunt.
Grunt lets you define a series of tasks that you can then run from the command line. You can chain them so that if one fails, the entire process fails. Basically, if you find yourself running multiple tasks multiple times, then a task runner like Grunt is a great way to simplify the process.
If you've never used Grunt before, check out the getting started guide for an introduction. After adding a package.json file to load in my required Grunt plugins (support for Jasmine, JSHint, and Uglify) I then built this Gruntfile.js:
module.exports = function(grunt) {
// Project configuration.
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
uglify: {
build: {
src: 'lib/swapi.js',
dest: 'lib/swapi.min.js'
}
},
jshint: {
all: ['lib/swapi.js']
},
jasmine: {
all: {
src:"lib/swapi.js",
options: {
specs:"tests/spec/swapiSpec.js",
'--web-security':false
}
}
}
});
grunt.loadNpmTasks('grunt-contrib-uglify');
grunt.loadNpmTasks('grunt-contrib-jshint');
grunt.loadNpmTasks('grunt-contrib-jasmine');
grunt.registerTask('default', ['jasmine','jshint','uglify']);
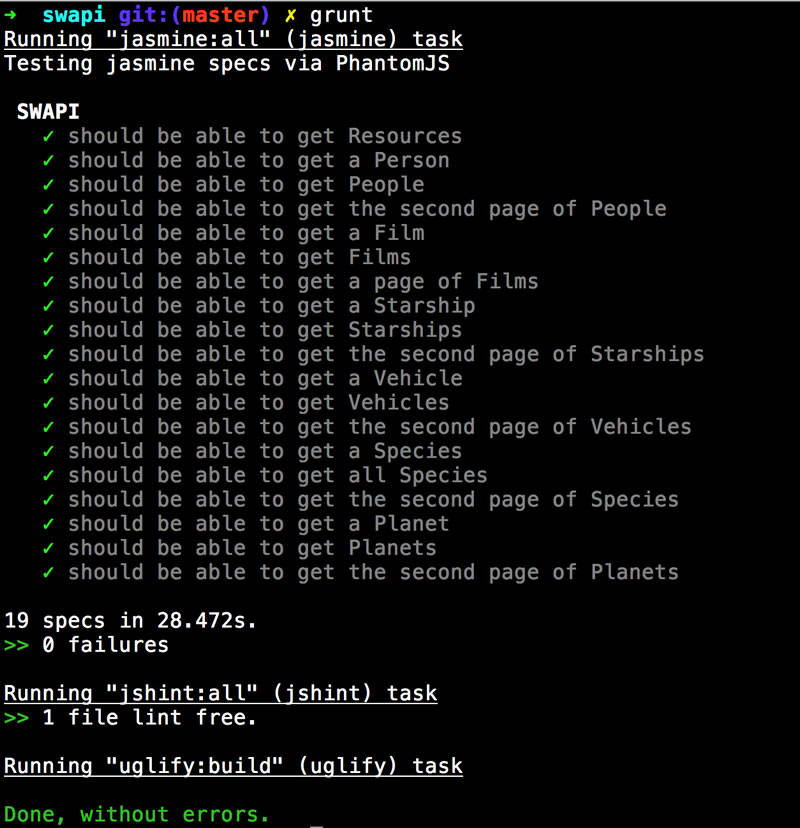
};Basically - run the unit tests (Jasmine), run JSHint, and then uglify. At the command line I can just type grunt to run all three.
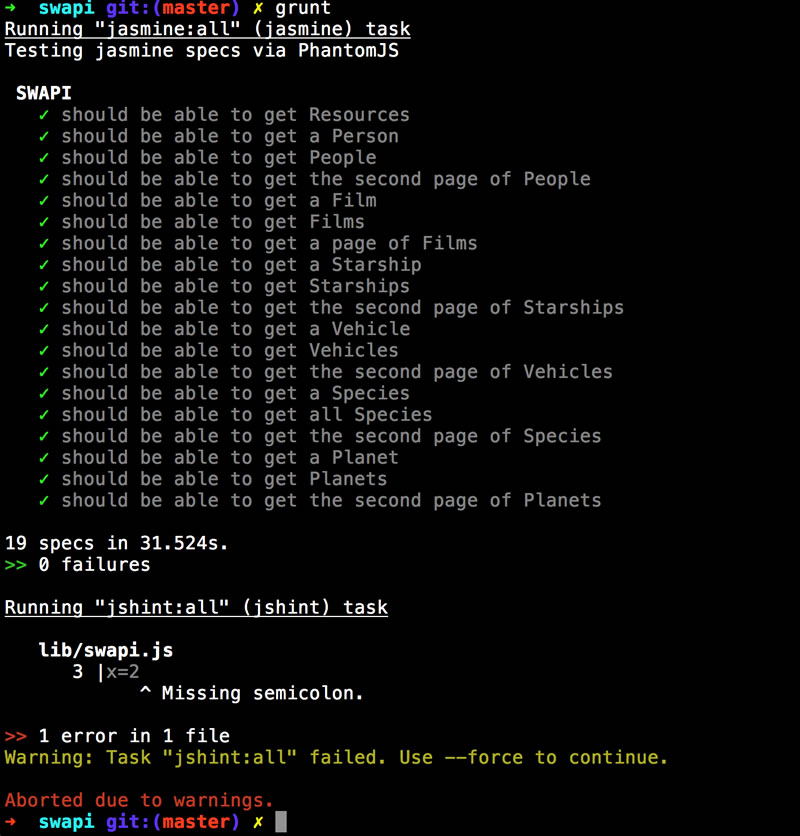
If I break something, like adding in code that will break JSHint, Grunt will report it and stop execution:
The Result?
At the end of all this, my original library isn't functionally improved as I never got around to looking at the code to make improvements, but look at what I've added:
- I have unit tests that check all the current functionality. When I start adding new features I can be sure I'm not breaking anything for people using the library. Really sure.
- I've used a linter to make sure my code matches generally accepted best practices. While not crucial, it's like having a second pair of eyes looking over my code. I like that.
- I've added a minified version of code library. While it doesn't provide huge savings, it is future-proof for when my library gets larger.
- I've automated the entire damn thing. Now I can do all of the above with one quick command. Life is awesome and I am an uber code ninja now.
I've now got a project that is just plain better and that's a great thing! You can see the final version of the project here.
Header image courtesy of JD Hancock

Raymond Camden
Raymond Camden is a senior developer advocate for Auth0 Extend. His work focuses on Extend, serverless, and the web in general. He's a published author and presents at conferences and user groups on a variety of topics. Raymond can be reached at his blog (www.raymondcamden.com), @raymondcamden on Twitter, or via email at raymondcamden@gmail.com.