
Step-by-Step Guide: Using LangExtract with OpenAI

Summarize with AI:
See how to get started with Google’s new LangExtract!
Recently, Google launched a library called LangExtract. LangExtract is an open-source Python library that enables developers to transform unstructured text into structured information using large language models (LLMs).
It offers a lightweight interface compatible with multiple model backends, including Gemini and GPT, making it well-suited for processing large unstructured text into structured information.
Some key features of LangExtract are:
- Multi-model support – Works with various LLM providers, including Gemini, Lama, GPT.
- Custom extraction rules – Define your own instructions to fit specific use cases.
- Lightweight interface – Minimal overhead for faster integration into existing workflows.
- Traceable outputs – Built-in mechanisms to monitor and verify how results are generated.
- High-volume processing – Efficient handling of large datasets without sacrificing control.
Installing Core Library
Let’s walk through, step by step, how to use LangExtract with the OpenAI GPT model. Start with installing the core library.
pip3 install langextract
Then to work with OpenAI GPT models, install the OpenAI integration:
pip3 install "langextract[openai]"
After installing the dependencies, import the necessary packages into your file.
import langextract as lx
Create a Prompt
The first step is to create a prompt that provides instructions to the model using the LangExtract library. Let’s define the prompt as shown below:
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")
Create an Example
Next, create an example to pass to the library. In the code below, we use the ExampleData function from the LangExtract library to define it. This example specifies different types of extraction classes, such as character and emotion.
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"}
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"}
),
]
)
]
Prepare Input Text
Next, prepare the input text that will be passed to LangExtract for analysis.
input_text = textwrap.dedent("""
The rain tapped softly against the old library windows, blurring the outline of the cobblestone streets beyond. Elara traced her fingers over the spine of a book she’d read a hundred times, feeling the faint indent of gold-pressed letters.
“Still looking for answers in those dusty pages?” asked a voice from the doorway.She turned, startled. It was Rowan, his coat dripping with rain. The same distant look lingered in his eyes, the one that always made her wonder what storms he carried inside.
“I’m not looking for answers,” she said quietly. “I’m trying to remember the right questions.”Rowan stepped into the room, the scent of damp earth and pine following him. “Then maybe I’ve found one for you.” He reached into his coat pocket and placed a small brass key on the desk. It was warm, as if it had been pressed in his palm for hours.
“Where did you get this?” Elara whispered.His gaze met hers, unflinching. “From the man who swore it could open something that should never be opened.”
The silence between them seemed to thicken, the air heavy with a secret neither was ready to speak.
""")
Call Extract
After defining the prompt, example and input text, we can call LangExtract’s extract function to retrieve the desired information from the provided text, as shown below.
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o",
api_key= os.getenv("OPENAI_API_KEY"),
fence_output=True,
use_schema_constraints=False
)
print("------result------")
print(result.extractions)
To work with OpenAI model, make sure to set the fence_output value to True. You should get extractions printed as below:
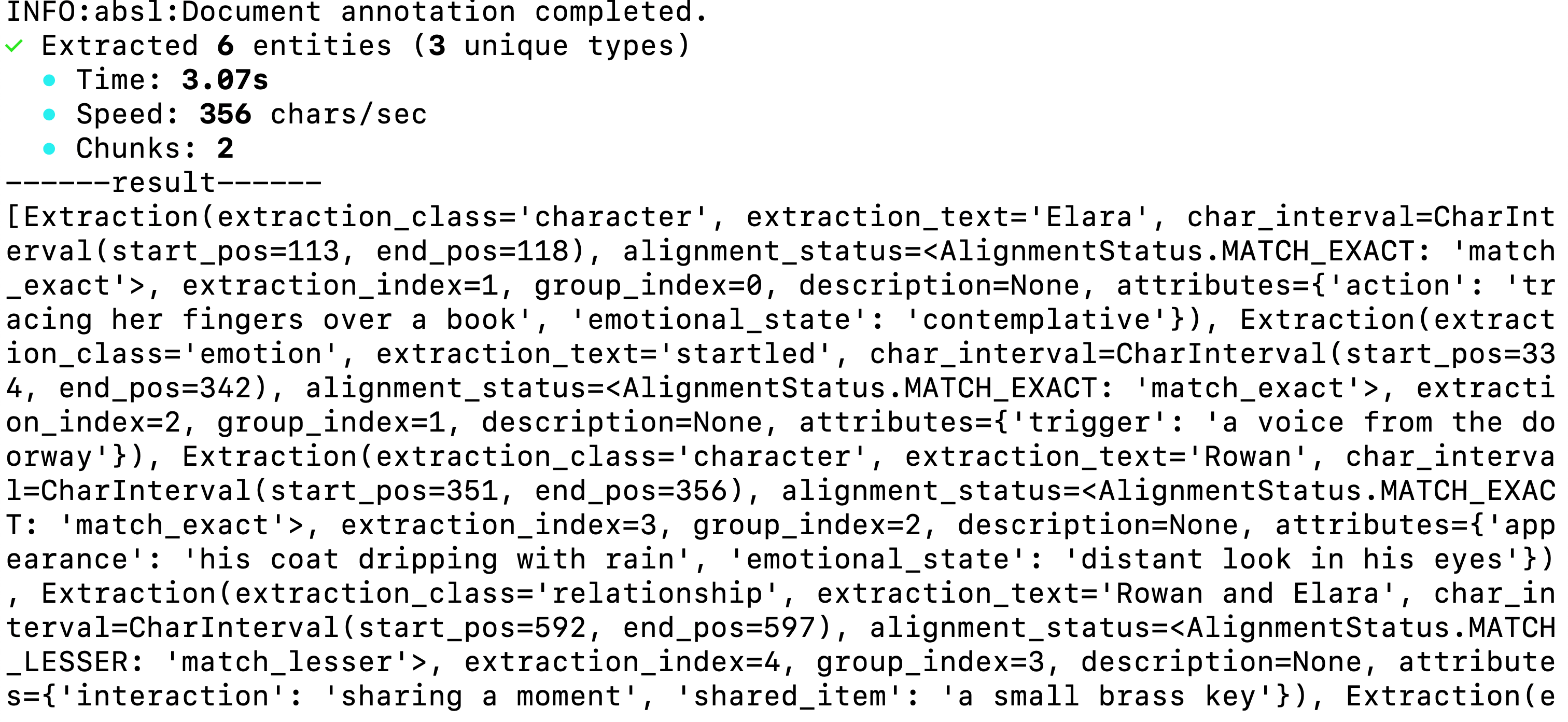
You can print all character names and the extractions as shown below.
character_names = [e.extraction_text for e in result.extractions if e.extraction_class == "character"]
print("=" * 40)
print("CHARACTER NAMES FOUND")
print("=" * 40)
for i, name in enumerate(character_names, 1):
print(f"{i}. {name}")
print("\n" + "=" * 40)
print("ALL EXTRACTIONS")
print("=" * 40)
for extraction in result.extractions:
print(f"📌 {extraction.extraction_class.upper()}: {extraction.extraction_text}")
if extraction.attributes:
print(f" Attributes: {extraction.attributes}")
print()
You should get the output as shown below:

You can also store the extracted data in a .jsonl file and visualize the results as shown below.
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl")
html_content = lx.visualize(result)
with open("visualization.html", "w") as f:
f.write(html_content)
When you open the HTML file in a browser, the visualization will appear as shown below.
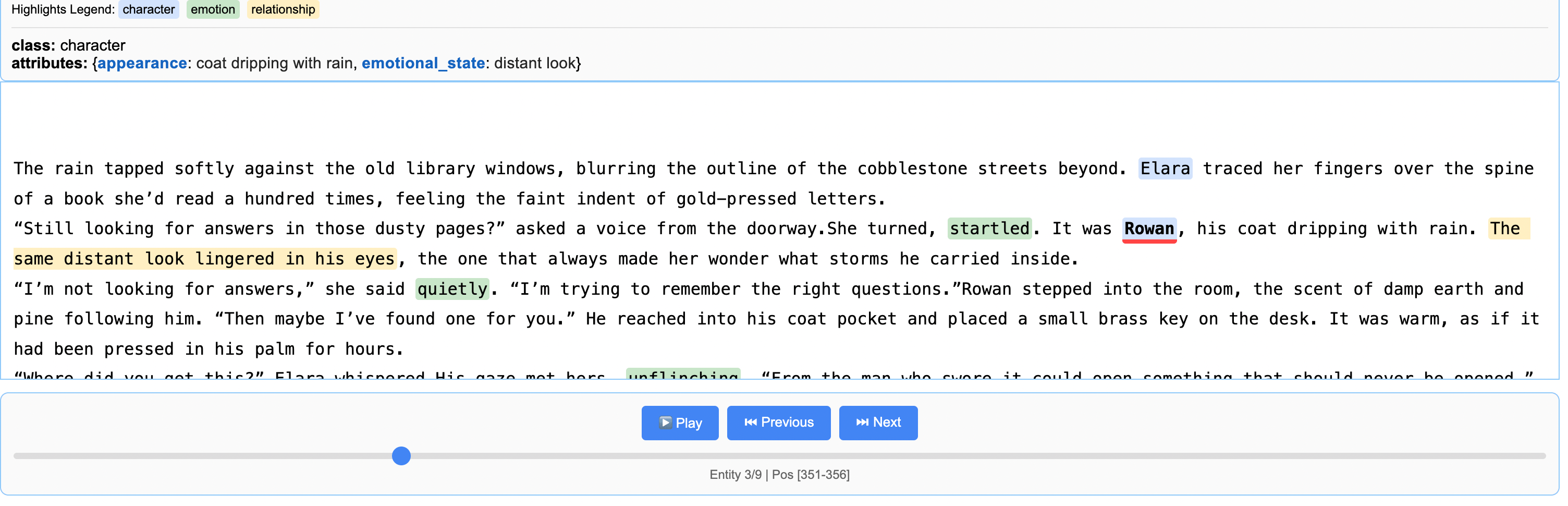
Altogether
Putting everything together, you can use Google’s LangExtract library with OpenAI GPT model as shown below:
import os
from dotenv import load_dotenv
from openai import OpenAI
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage
from langchain_core.messages import AIMessage, SystemMessage
from langchain_core.prompts import PromptTemplate
import textwrap
import langextract as lx
load_dotenv()
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")
input_text = textwrap.dedent("""
The rain tapped softly against the old library windows, blurring the outline of the cobblestone streets beyond. Elara traced her fingers over the spine of a book she’d read a hundred times, feeling the faint indent of gold-pressed letters.
“Still looking for answers in those dusty pages?” asked a voice from the doorway.She turned, startled. It was Rowan, his coat dripping with rain. The same distant look lingered in his eyes, the one that always made her wonder what storms he carried inside.
“I’m not looking for answers,” she said quietly. “I’m trying to remember the right questions.”Rowan stepped into the room, the scent of damp earth and pine following him. “Then maybe I’ve found one for you.” He reached into his coat pocket and placed a small brass key on the desk. It was warm, as if it had been pressed in his palm for hours.
“Where did you get this?” Elara whispered.His gaze met hers, unflinching. “From the man who swore it could open something that should never be opened.”
The silence between them seemed to thicken, the air heavy with a secret neither was ready to speak.
""")
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"}
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"}
),
]
)
]
def extract_text():
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o",
api_key= os.getenv("OPENAI_API_KEY"),
fence_output=True,
use_schema_constraints=False
)
print("------result------")
print(result.extractions)
character_names = [e.extraction_text for e in result.extractions if e.extraction_class == "character"]
print("=" * 40)
print("CHARACTER NAMES FOUND")
print("=" * 40)
for i, name in enumerate(character_names, 1):
print(f"{i}. {name}")
print("\n" + "=" * 40)
print("ALL EXTRACTIONS")
print("=" * 40)
for extraction in result.extractions:
print(f"📌 {extraction.extraction_class.upper()}: {extraction.extraction_text}")
if extraction.attributes:
print(f" Attributes: {extraction.attributes}")
print()
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl")
html_content = lx.visualize(result)
with open("visualization.html", "w") as f:
f.write(html_content)
return html_content
if __name__ == "__main__":
extract_text()
You can follow updates to the library here: https://github.com/google/langextract. I hope this article helps you get started with LangExtract and explore its vast potential for a wide range of use cases. Thanks for reading.

Dhananjay Kumar
Dhananjay Kumar is the founder of nomadcoder, an AI-driven developer community and training platform in India. Through nomadcoder, he organizes leading tech conferences such as ng-India and AI-India. He partners with startups to rapidly build MVPs and ship production-ready applications. His expertise spans Angular, modern web architecture and AI agents, and he is available for training, consulting or product acceleration from Angular to API to agents.
Related Posts
Comments
All articles
Topics
Web MobileMobile
Desktop
Design
Productivity
People
