
GraphQL: Schema, Resolvers, Type System, Schema Language, and Query Language

Summarize with AI:
In this article, I cover some fundamental concepts of GraphQL and show how to build a server that responds to two query operations.
GraphQL has been gaining wide adoption as a way of building and consuming Web APIs. GraphQL is a specification that defines a type system, query language, and schema language for your Web API, and an execution algorithm for how a GraphQL service (or engine) should validate and execute queries against the GraphQL schema. It is upon this specification that the tools and libraries for building GraphQL applications are built.
In this post, I'll introduce you to some GraphQL concepts with a focus on GraphQL schema, resolver, and the query language. If you'd like to follow along, you need some basic understanding of JavaScript (especially arrow functions in ES6) and Node.js. Without further ado, let's get started setting up our development environment.
Creating the Project
We will be building a GraphQL server that will respond to requests to perform the different operation types in GraphQL. Open your terminal, navigate to the directory of your choice, and run the commands below:
mkdir graphql-intro && cd graphql-intro
npm init -y
npm install graphql-yogaThose instructions were used to create a folder for the project, initialize a new Node.js project, and add the graphql-yoga dependency to the project. graphql-yoga is a library that helps you build GraphQL server applications easily by providing sensible defaults, and includes other GraphQL libraries such as subscriptions-transport-ws which is a WebSocket server for GraphQL subscriptions, apollo-server which is a web server framework, and graphql-playground which is an interactive GraphQL IDE that you can use to test your server.
With the dependencies installed, we will now go ahead and define our GraphQL schema.
The GraphQL Schema
The GraphQL schema is at the center of every GraphQL server. It defines the server's API, allowing clients to know which operations can be performed by the server. The schema is written using the GraphQL schema language (also called schema definition language, SDL). With it, you can define object types and fields to represent data that can be retrieved from the API as well as root types that define the group of operations that the API allows.
The root types are the query type, mutation type, and subscription type, which are the three types of operations you can run request from a GraphQL server. The query type is compulsory for any GraphQL schema, while the other two are optional. While we can define custom types in the schema, the GraphQL specification also defines a set of built-in scalar types. They are Int, Float, Boolean, String, and ID.
Let's go ahead and create a schema. Add a new file src/index.js with the following content:
const typeDefs = `
type Book {
id: Int!
title: String!
pages: Int
chapters: Int
}
type Query {
books: [Book!]
book(id: Int!): Book
}
`;What we have above is the GraphQL schema. In it, we defined a Book type with four fields and a root Query type with two fields. The two fields in the root Query type defines what queries/operations the server can execute. The books field returns a list of Book type, and the book field will return a Book type based on the id passed as an argument to the book query.
Every field in a GraphQL type can have zero or more arguments. There's an exclamation mark that follows the scalar types assigned to some fields. This means that the field or argument is non-nullable.
Implementing Resolvers
Our API is able to run two query operations: one to retrieve an array of books and another to retrieve a book based on its id. The next step for us is to define how these queries get resolved so that the right fields are returned to the client.
The way to do this is by defining a resolver function for every field in the schema. Remember that I mentioned that GraphQL has an execution algorithm? The implementation of this execution algorithm is what transforms the query from the client into actual result, by moving through every field in the schema, and executing their “resolver” function to determine its result.
Add the code below to index.js:
const books = [{
id: 1,
title: "Fullstack tutorial for GraphQL",
pages: 356
}, {
id: 2,
title: "Introductory tutorial to GraphQL",
chapters: 10
}, {
id: 3,
title: "GraphQL Schema Design for the Enterprise",
pages: 550,
chapters: 25
}];
const resolvers = {
Query: {
books: function(root, args, context, info) {
return books;
},
book: (root, args, context, info) => books.find(e => e.id === args.id)
},
Book: {
id: parent => parent.id,
title: parent => parent.title,
pages: parent => parent.pages,
chapters: parent => parent.chapters
}
};In the code you just added, we defined a variable to hold our data in memory. There'll be no database access in this post. The resolvers variable is an object that contains resolvers for our types. The fields in the properties are named after the types in our schema, and they're objects with the fields we defined for that type in the schema. The fields each define their resolver function, which will be executed by the GraphQL engine and it should resolve to the actual data for that field. You'll notice that the functions in the Query type have a declaration like this:
function (root, args, context, info) { // function implementation }Note that I have used the arrow function syntax in ES6 to declare some resolver functions in the code.
Those are the four (4) arguments that every resolver function receives. They're described as:
root: This argument is sometimes calledparent. It contains the result of the previously executed resolver in the call chain. For example, if we call thebookquery, it'll start executing from the root fieldbookin the Query root type. After that, it'll execute the resolvers in theBooktype to get values for those fields. In the code above, I named the first argument for the resolvers of the fields inBookasparent. The value for the argument will be the Book object received from the parent resolver. This is why we're callingparent.title, for example, to return value for that field.args: These are the arguments provided to the field in the GraphQL query. Following our example, this will be theidargument for thebookquerybook(id: Int!): Book.context: This is an object that every resolver can read from or write to. You can keep objects that give access to database or that contain information from the HTTP request headers here. Unlike the root and args parameters, their values vary based on what level in the execution chain the resolver is called from. The context object is the same across resolvers, and you can write contextual information to it as needed. We will use this argument in the next post, so stay tuned!info: Taking definition from here, it holds field-specific information relevant to the current query as well as the schema details. To learn more about it, you can read this excellent post on the subject.
Setting Up The Server
Having defined our schema and resolvers, we will go ahead and set up the GraphQL server. Still having index.js open, update it with the following code:
const { GraphQLServer } = require("graphql-yoga");
const typeDefs = ...// schema definition from previous section
const books = [
// array of books object from previous section
];
const resolvers = { ... };
const server = new GraphQLServer({
typeDefs,
resolvers
});
server.start(() => console.log(`Server is running on http://localhost:4000`));Here we imported GraphQLServer from the graphql-yoga library and used it to create a server object with our schema definition and resolvers. With this, our server is complete. It knows which API operation to process and how to process it. Let's go ahead and test the server.
GraphQL Query Language
Open the command line and run the command node src/index.js to start the server. You should see Server is running on http://localhost:4000 logged in the console. Open your browser to that URL. It will display a nice-looking interface. This is the GraphQL playground. It allows you to test the server operations. If you've built REST APIs, think of it as a Postman alternative for GraphQL.
Now let's ask the server to give us all the books it has. How do we do this? We do this using the GraphQL query language, another concept of GraphQL that makes it easy for different devices to query for data as they want, served from the same GraphQL API.
Go to the GraphQL playground and run the following query:
query {
books {
id
title
chapters
}
}You should get same result as follows
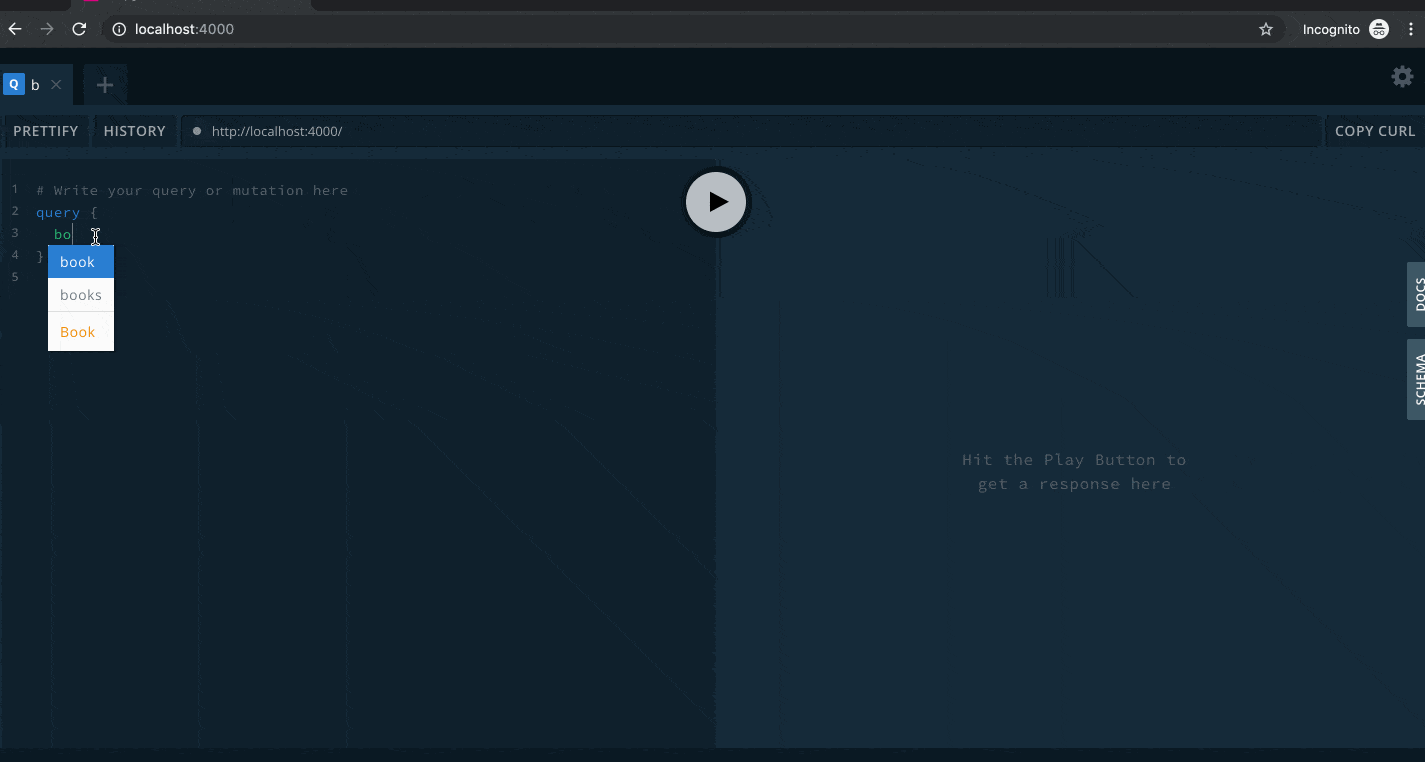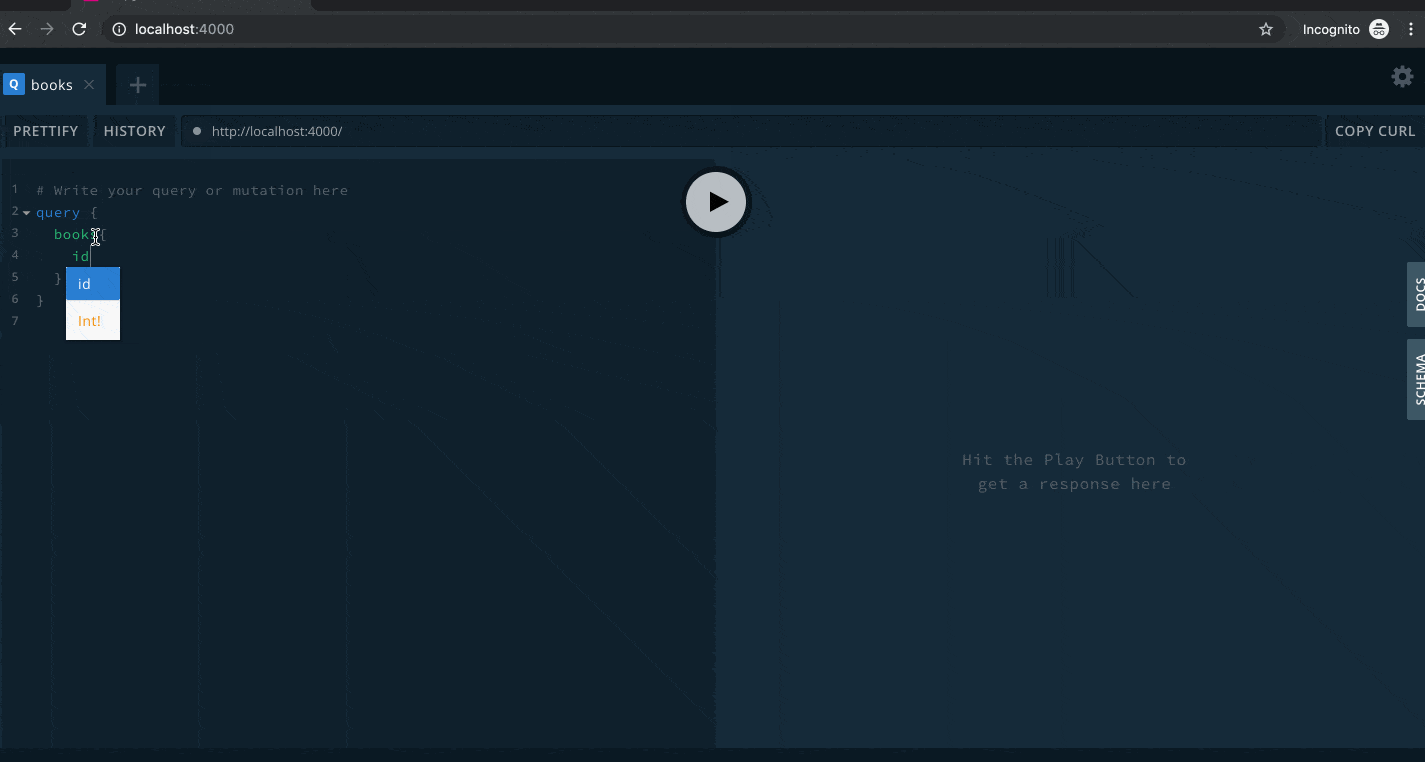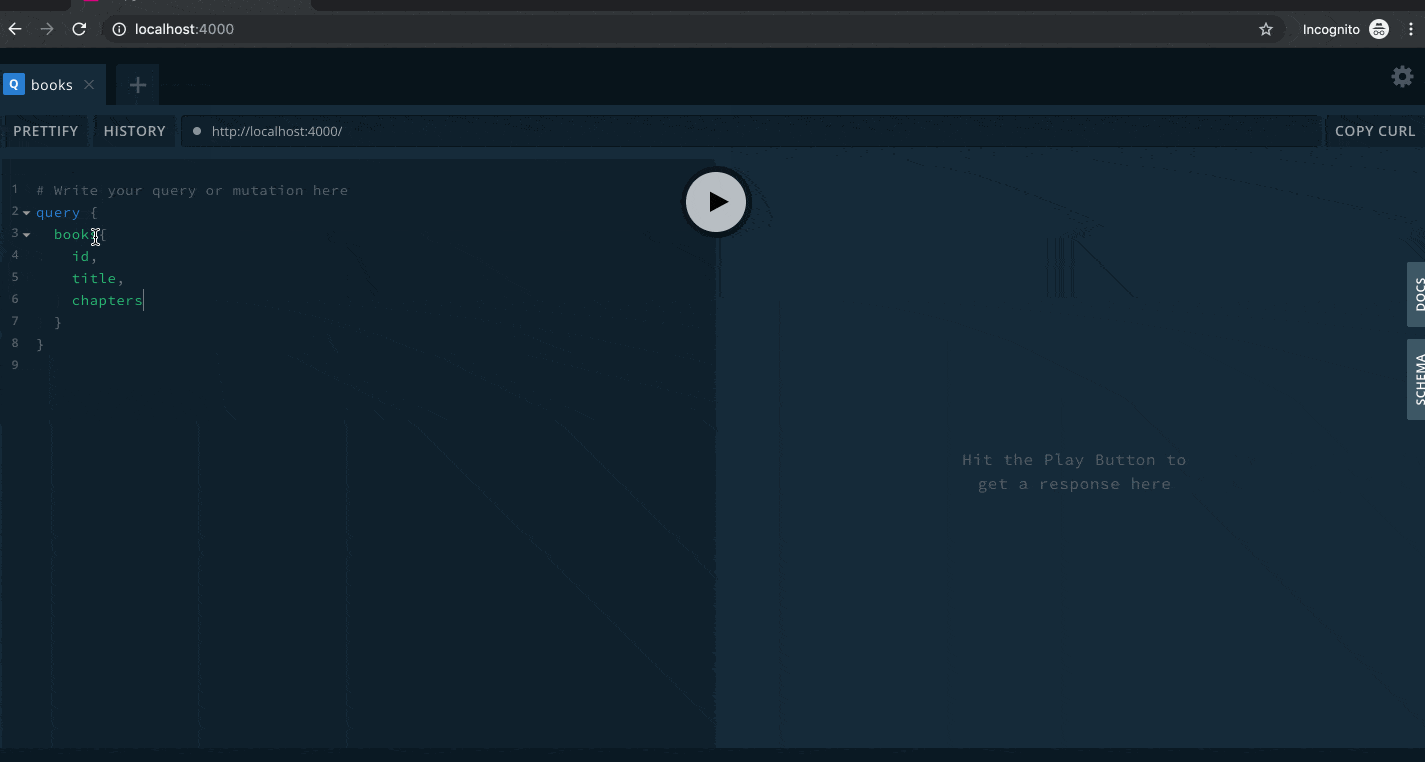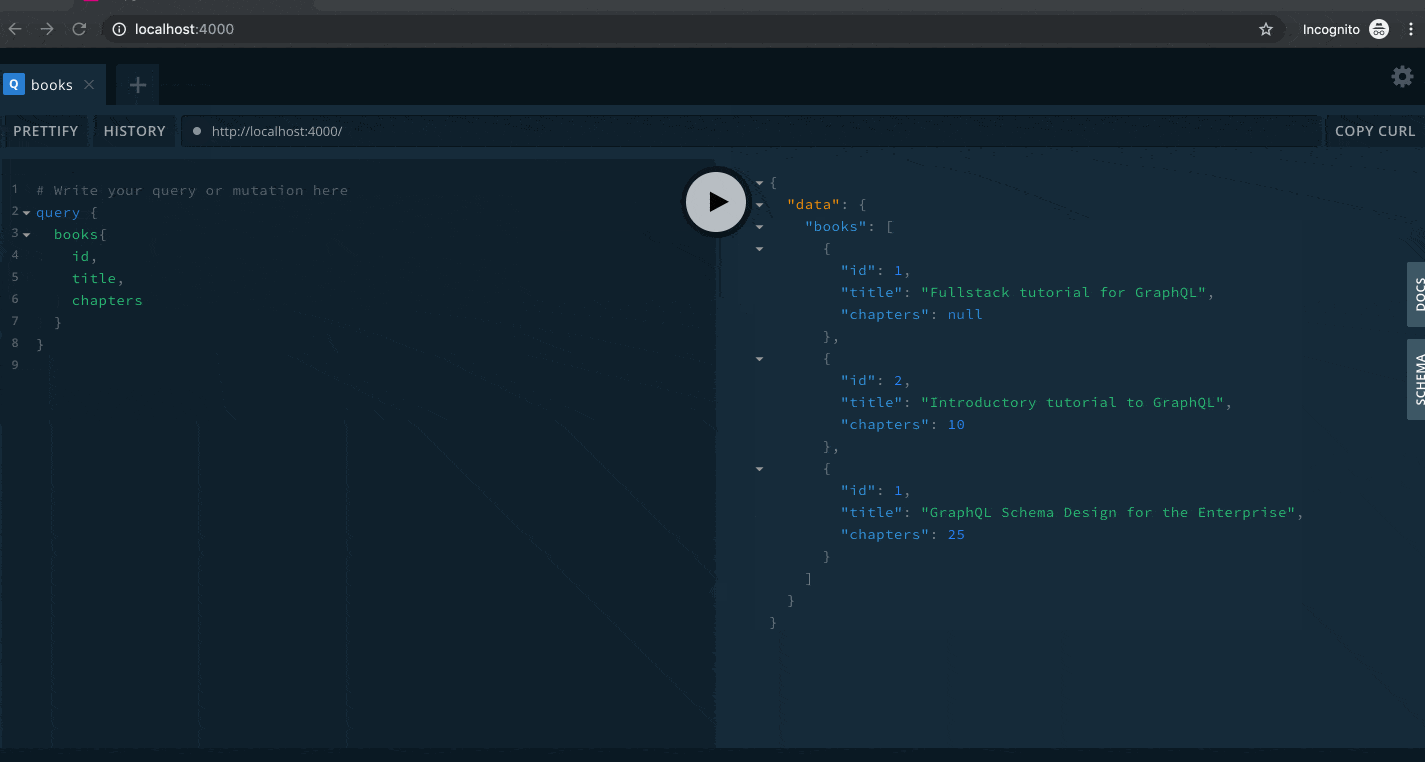
You'll notice that the query is structured similar to the schema language. The books field is one of the root fields defined in the query type. Then inside the curly braces we have the selection set on the books field. Since this field will return a list of Book type, we specify the fields of the Book type that we want to retrieve. We omitted the pages field, therefore it is not returned by the query.
We can test the book(id) query and see what it gives us.
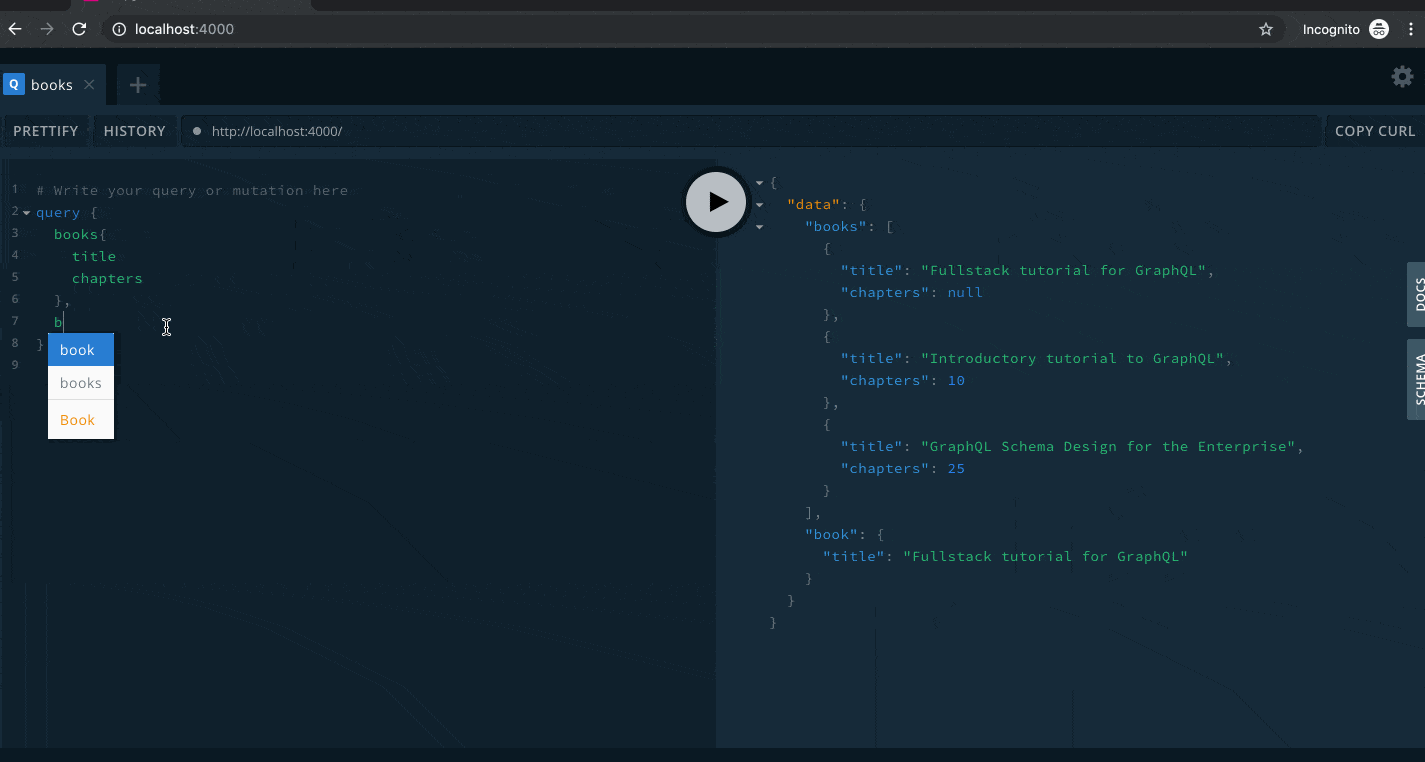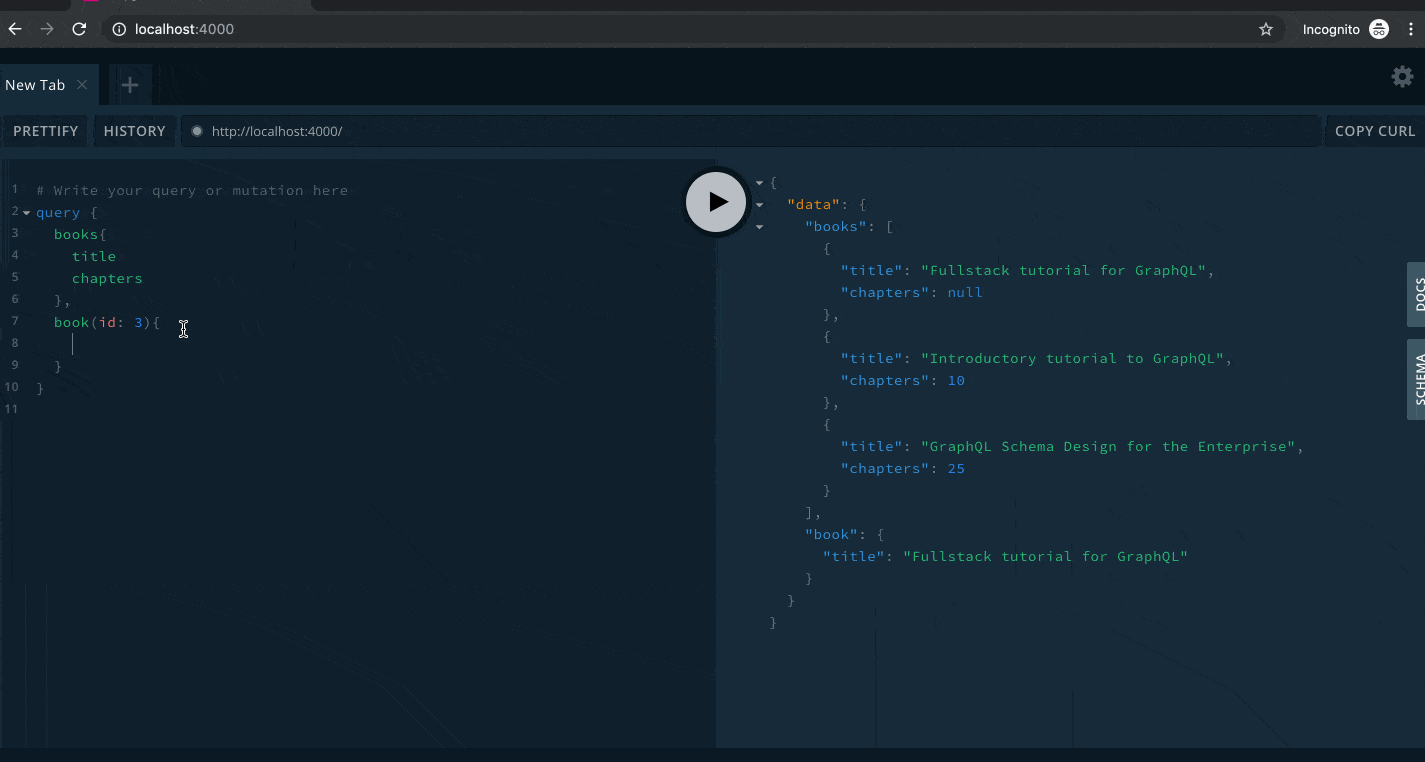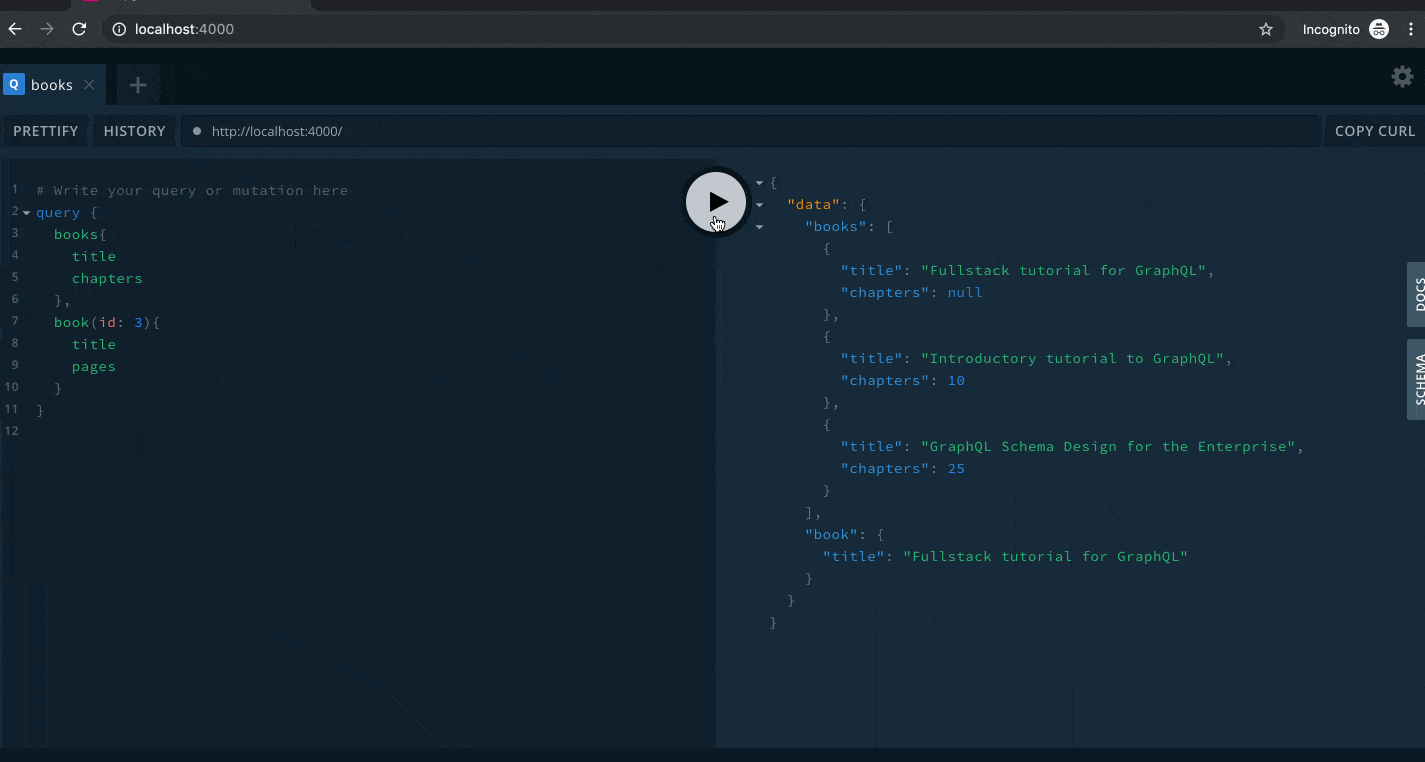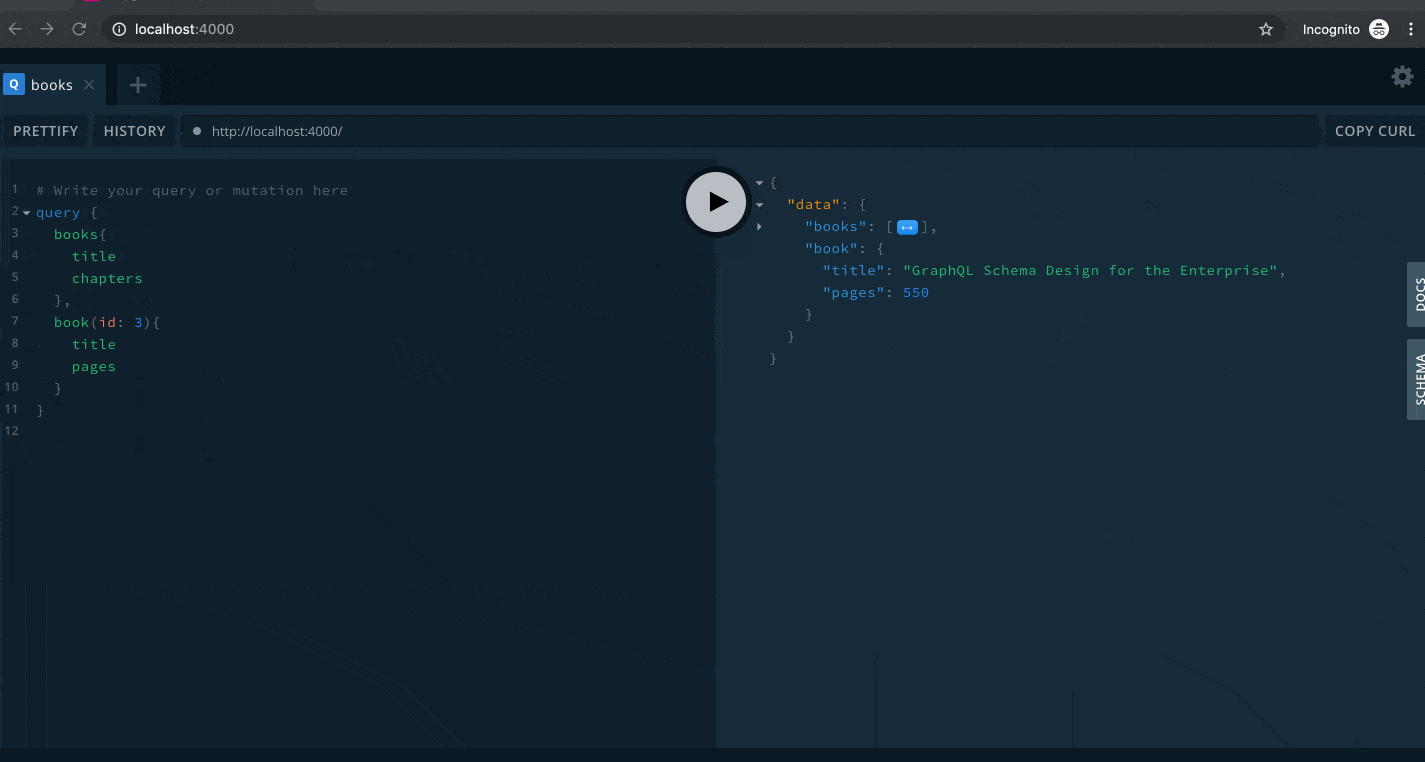
In this query we set the id argument to a value of 3, and it returned exactly what we need. You'll notice I have two queries, books and book(id: 3). This is a valid query. The GraphQL engine knows how to handle it.
What's Next?
So far I've covered some basics of GraphQL. We looked at defining a schema using the schema definition language, writing resolver functions, and querying the GraphQL API. I explained the four parameters that every resolver function receives, and we used one of the parameters to resolve fields for the Book type. We created our server using graphql-yoga and used GraphQL playground to test our API. I explained that in GraphQL we have three operation types.
In this post, we worked with the query operation, and in the next post, we'll look at mutations and accessing a database to store and retrieve data. We will update our schema so we can query for related data, e.g Authors with their books, or books from a particular publisher. So stay tuned!
Here's a link to the GitHub project if you did not follow along writing the code yourself.

Peter Mbanugo
Peter is a software consultant, technical trainer and OSS contributor/maintainer with excellent interpersonal and motivational abilities to develop collaborative relationships among high-functioning teams. He focuses on cloud-native architectures, serverless, continuous deployment/delivery, and developer experience. You can follow him on Twitter.