
Alexa, Can I Use?

Summarize with AI:
A lot of the talk about building applications for devices focuses on the user interface (UI). Rightly so, as the UI can be the single most challenging aspect of developing an application, especially on mobile devices which present new constraints on size and interaction. However, there are a new breed of apps that have grown in popularity recently that have zero UI that some argue represent the future of the web. These include written interfaces like bots as well as natural, spoken language interfaces like Amazon's Alexa.
In this article, we'll explore how to build an app (aka "skill") for Amazon's Alexa. We'll explore some of the unique challenges to application development when the only means of input and output is spoken language. I'll discuss an experimental application I built for Alexa that allows the user to ask for browser feature support using data from Can I Use.
Since I first created this skill, someone has since released a Can I Use bot for Slack, which performs a similar task but with text rather than voice.
What Is Alexa?
Alexa is the voice service that most famously runs the Amazon Echo but has also begun to appear on other Amazon products such as the recent Echo Dot and Tap. It was also recently added to the Fire TV. It functions much like Siri or Cortana, with a couple of important distinctions.

The first distinction is that there is no option for visual output on devices like the Echo and Echo Dot. This means that, unlike Siri or Cortana, there is no equivalent option to bringing up something like a web page, search results or a map in response to a query. Your only option for responding is with voice. (Yes, there is an Alexa app that does have a UI, but it is typically not a requirement for Alexa's use.)
The second distinction is that Amazon has chosen to let individuals and companies leverage Alexa either by integrating its voice services into their own devices or by building apps (call skills) for Alexa.
In addition, there are two types of skills, a "smart home skill" that adds Alexa integration with various smart home devices. This allows users to control aspects of their home, such as turn on the lights or change the temperature, using their voice. However, a standard skill simply responds to a user's query. You ask Alexa a question and, assuming it has the skill, it answers. It's the latter type of skill we're going to explore today.
Creating Skills for Alexa
Alexa skills can be created using JavaScript and Node.js that is deployed to Amazon Web Services. It'll require a free AWS plan (though they will ask for a credit card) and an Amazon developer account, which is also free.
This article won't walk you through all the steps to setting up your accounts, however, Amazon's tutorial for creating a fact skill has detailed instructions on how to set up your accounts (note: some of the images are slightly outdated, but the steps should still be fairly obvious). There is also fairly thorough documentation regarding the Alexa Skills Kit which, as its name implies, allows you to develop new skills for Alexa.
I'll focus on the code required to create the skill and getting that code uploaded and tested both in the browser and on an Echo as well as the complexity in converting data to spoken language.
A Starting Point
Amazon has created a number of skills templates that are available on GitHub. They include everything from a simple "Hello World" to a more complex skill that calls an API. It's a good reference point if you plan to develop for Alexa.
I used the Minecraft Helper sample as my starting point. This sample works off a fixed list of potential queries defined by a custom slot type, which is what we'll need to use for the Can I Use data - more on that later.
The Data
Can I Use posts its raw data in JSON format to its GitHub project, which means we'll be pulling from a static file containing data rather than a remote API. The data is laid out in a way that supports the site that it powers, meaning that it is designed to be presented in tables, which will pose some issues for converting it to spoken responses.
To begin, I used a JSON Viewer to explore the data and try to understand its structure.
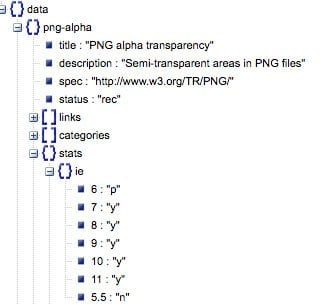
What I needed to do was:
- Turn this into a static list of query values (known as a custom slot type in Alexa terminology). So, this would allow me to ask Alexa about "PNG alpha transparency" in the data pictured above.
- Translate the data into a response that can be spoken by Alexa.
Generating a Custom Slot Type
The custom slot type defines all of the values that a user can ask Alexa about for the new skill.
"The custom slot type is used for items that are not covered by Amazon’s built-in set of types and is recommended for most use cases where a slot value is one of a set of possible values." - source
In this example, the custom slot type would contain all of the HTML, CSS and JavaScript features that Can I Use has data about. This list is supplied to the Alexa service in plain text. There are well over 300 potential values, so this is not a list that I want to manually create and update.
In order to solve this, I created a simple export.js file that I could run and would convert the each of the features into a text list that can be supplied to Alexa. Since Alexa looks for an exact match, I used both the full feature title as well as the key name to give the user more options to speak (so, you can say both "video" and "video element" for instance). I also stripped all the special characters, as you can't speak these.
var data = require('./data'),
fs = require('fs'),
features = '',
featureModule = 'module.exports = {\n',
allKeys = [],
key;
for (var item in data.data) {
if (data.data.hasOwnProperty(item)) {
// remove special characters and then duplicate spaces it creates
key = data.data[item].title.replace(/[^a-zA-Z0-9 ]/g, " ").trim().replace(/ +(?= )/g,'')
if (allKeys.indexOf(key.toLowerCase()) == -1) {
allKeys.push(key.toLowerCase());
features += key + '\n';
featureModule += '"' + key.toLowerCase() + '" : "' + item + '",\n';
}
// add in the key itself without special chars as it often strips the feature to a simplified version
key = item.replace(/[^a-zA-Z0-9 ]/g, " ").trim().replace(/ +(?= )/g,'');
if (allKeys.indexOf(key.toLowerCase()) == -1) {
allKeys.push(key.toLowerCase());
features += key + '\n';
featureModule += '"' + key.toLowerCase() + '" : "' + item + '",\n';
}
}
}
featureModule = featureModule.substring(0, featureModule.length-2);
featureModule += "\n};"
fs.writeFile("../../speechAssets/customSlotTypes/LIST_OF_FEATURES", features, function(err) {
if(err) {
return console.log(err);
}
console.log("The file was saved!");
});
fs.writeFile("../features.js", featureModule, function(err) {
if(err) {
return console.log(err);
}
console.log("The file was saved!");
});You'll notice that I am actually creating two files. The second, features.js, will be used in the application code to map the spoken query to the appropriate data key in the JSON data. This allows the application to know that when I say something like "filereader API," I am referring to the data key of "filereader."
You can see the full final list of features here. This will be supplied to the Alexa service later.
Creating the Intent Schema and Utterances
To configure an Alexa skill, you need something called an Intent Schema JSON file. This will define things like the custom slot type as well as the methods (i.e. intents) that Alexa will respond to. In my case, I had one primary intent with one custom slot type (as you can see below, I've given it a name of Feature from a type of LIST_OF_FEATURES - these values will be important). The other intents are standard for responding to things like "help" and "cancel" that I borrowed from the sample file.
{
"intents": [
{
"intent": "CanIUseIntent",
"slots": [
{
"name" : "Feature",
"type": "LIST_OF_FEATURES"
}
]
},
{
"intent": "AMAZON.HelpIntent"
},
{
"intent": "AMAZON.StopIntent"
},
{
"intent": "AMAZON.CancelIntent"
}
]
}The utterances are the various things a user can say to Alexa in order to activate this skill. Usually, you'll want to have a ton of these to cover variations in speech. This task can be more difficult that you might think and, in fact, it held up approval of my skill. Amazon does offer some advice on how to develop your utterances. Here is the final list of utterances for my skill.
CanIUseIntent {Feature}
CanIUseIntent what is the browser support for {Feature}
CanIUseIntent tell me browser support for {Feature}
CanIUseIntent what browsers support {Feature}
CanIUseIntent does {Feature} work in Internet Explorer
CanIUseIntent does {Feature} work in Chrome
CanIUseIntent does {Feature} work in Opera
CanIUseIntent does {Feature} work in Edge
CanIUseIntent does {Feature} work on mobile browsers
CanIUseIntent do mobile browsers support {Feature}
CanIUseIntent can I use {Feature}Notice how Feature in the utterances above refers to Feature in the Intent Schema. This is how the service knows that the name of the feature I intend to query (i.e. the one that matches one of the custom slot type values above) follows the phrase "can I use."
These files will be supplied to the Alexa service later as well.
Creating the Skill
The skill code is made up of two primary files: index.js and AlexaSkill.js. AlexaSkill.js is simply the same as the provided sample - no changes necessary.
index.js needs to require AlexaSkill.js. Mine also imports the features.js file generated earlier, the data.json file and a module I called createResponse.js that we'll discuss in a bit.
var AlexaSkill = require('./AlexaSkill'),
features = require('./features'),
data = require('./data/data'),
createResponse = require('./createResponse');Let's look at the primary intent method called CanIUseIntent (note: I won't look at the help, cancel or other intents as the only thing different from the sample is the text of the response for help).
"CanIUseIntent": function (intent, session, response) {
var featureSlot = intent.slots.Feature,
featureName;
if (featureSlot && featureSlot.value){
featureName = intent.slots.Feature.value.toString().toLowerCase();
}
var cardTitle = "Can I use " + featureName,
feature = features[featureName],
featureResponse,
speechOutput,
repromptOutput;
if (feature == undefined) {
featureResponse = "I'm sorry, I currently do not know the feature for " + featureName + ".";
}
else {
featureResponse = createResponse(data,data.data[feature]);
}
speechOutput = {
speech: featureResponse,
type: AlexaSkill.speechOutputType.PLAIN_TEXT
};
response.tellWithCard(speechOutput, cardTitle, feature);
}The code here is relatively simple. First, I get the value that is passed by the custom slot type, which is available as intent.slots.Feature (remember, I gave it the name Feature within the intent schema). This value is used to search for a matching key in the features.js file I generated earlier. Assuming it does find a match, I pass this data to a createResponse() method that will return the text of our response. This is where things get slightly more complicated.
Turning Data into Speech
There are two parts to turning Can I Use data into a spoken language response. The first is determining what we want to return. There is a lot of data about various browser versions, which makes sense given the support table that Can I Use is known for. However, this does not make sense for a spoken response.

The fist assumption I made is that a user wouldn't typically care about every version Can I Use has data on, but only the widely used mobile and desktop browsers that the site lists by default. I started by mapping these out so that the key in the data (i.e. "ie") maps to what I want Alexa to say (i.e. "Internet Explorer"). I kept mobile and desktop separate so that I could make a more comprehensible response - as we'll explore momentarily.
var desktop = {
"ie":"Internet Explorer",
"edge":"Edge",
"firefox":"Firefox",
"chrome":"Chrome",
"safari":"Safari",
"opera":"Opera"
}
var mobile = {
"ios_saf":"IOS Safari",
"op_mini":"Opera Mini",
"android":"Android Browser",
"and_chr":"Android Chrome"
}The other assumption was that a person asking Alexa something like "Can I use arrow functions?" would be primarily interested in support on the current version of browsers rather than all prior or future versions. On the site, the current version is the one with the dark gray background (see the image above).
Unfortunately, in the data, it is not obvious which is the current version - it takes a little bit of massaging of the data.
// figure out which key is the current version. not sure if this ever changes
var eras = Object.keys(data.eras),
current = eras.indexOf('e0');
// now get the current version for each of the above browsers
for (var desk_browser in desktop) {
currentVersion = data.agents[desk_browser].versions[current];
if (feature.stats[desk_browser][currentVersion] == 'y') {
desk_supported.push(desktop[desk_browser]);
}
else if (feature.stats[desk_browser][currentVersion] == 'n') {
desk_unsupported.push(desktop[desk_browser]);
}
else {
desk_partial.push(desktop[desk_browser]);
}
}I repeat the same loop for the mobile browsers as well. As you can see, I separated them into three categories: fully supported, partially supported and unsupported. The Can I Use data and site has a much greater level of detail, but, again, that doesn't make sense from a spoken response standpoint.
Now that I have the data sorted, it's time to compile it into a response. In the below code, I am assembling the desktop portion of the response.
// determine our response
if (desk_unsupported.length == 0 && desk_partial.length == 0) {
response = 'The feature is fully supported on desktop browsers';
}
else if (desk_unsupported.length == 0) {
response = 'The feature is supported on the desktop but only partially on ' + desk_partial.join(',');
}
else if (desk_supported.length == 0 && desk_partial == 0) {
response = 'The feature is unsupported on desktop browsers.'
}
else if (desk_supported.length == 0) {
response = 'On desktop, the feature is partially supported on ' + desk_partial.join(',') + '. It is unsupported on ' + desk_unsupported.join(',');
}
else if (desk_partial.length == 0) {
response = 'On desktop, the feature is supported on ' + desk_supported.join(',') + '. It is unsupported on ' + desk_unsupported.join(',');
}
else {
response = 'On desktop, the feature is supported on ' + desk_supported.join(',') + '. The feature is partially supported on ' + desk_partial.join(',') + '. It is unsupported on ' + desk_unsupported.join(',');
}There are more efficient ways to handle this from a code standpoint, but I chose to manually create each response separately to allow me to customize it slightly based upon the nature of the support being shared. It would have been easy to create a responselike "It is supported on X, Y, Z. It is unsupported on A, B," but, to me, that would sound very robotic and unnatural.
I repeat the same code above for mobile and append that to the response that the method returns as a string.
Uploading and Testing
After setting up an AWS account and creating a Lambda Function (again, follow the detailed instructions here), you'll prompted to upload the code that runs the skill. In this case, it is only the code under the src folder - everything under the speechAssets folder is needed later. Just zip up all the files (as in, everything in the src directory but not the src directory itself) and upload it. (You can download the zip here.)
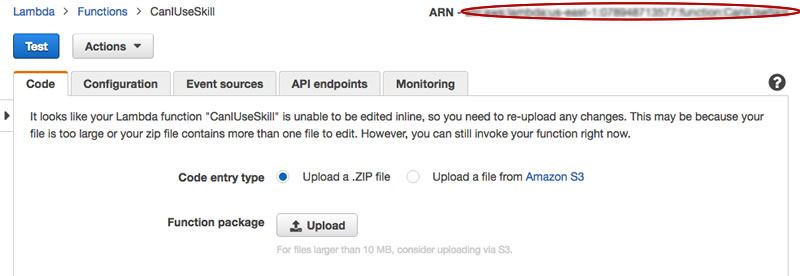
As you make changes to your Alexa skill, you'll be uploading a new zip every time. Take note of the ARN in the right hand corner (I've blurred mine out), which is necessary when setting up the Alexa Skill.
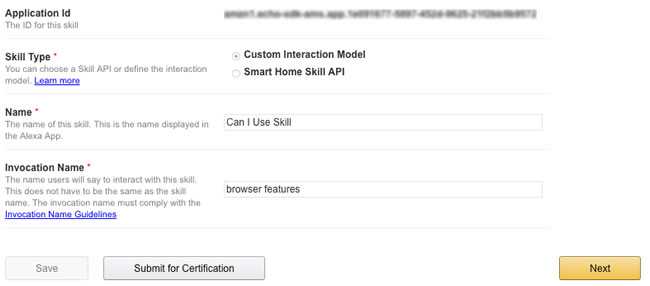
Next I set up my Alexa skill. First, I set the basic info including the skill's name and invocation name, which is what a user says to activate the skill. I would have loved to use "can I use" as the invocation name, but according to Amazon's rules this was deemed too generic (and I can see that), so I used "browser features." The Application id is important if you intend to publish the skill.
The next step is setting up the interaction model, which is where you make use of the various speech assets. Paste in the intent schema.
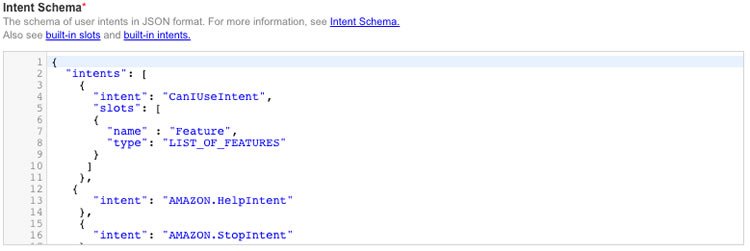
Next, click to add a custom slot type. Make sure the type is the same as specified in the intent schema and paste in the values.
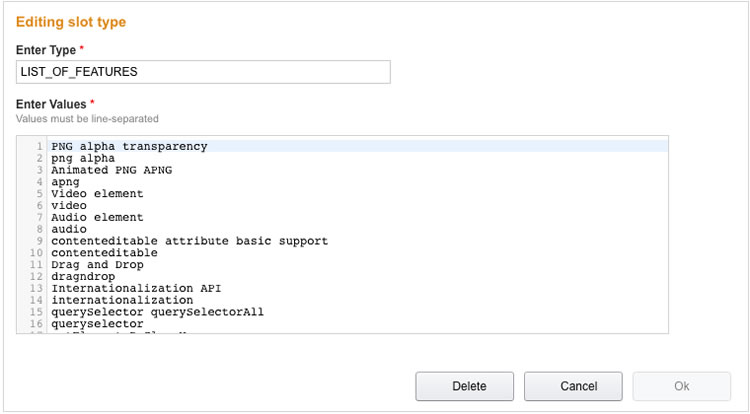
Finally, paste in the sample utterances.
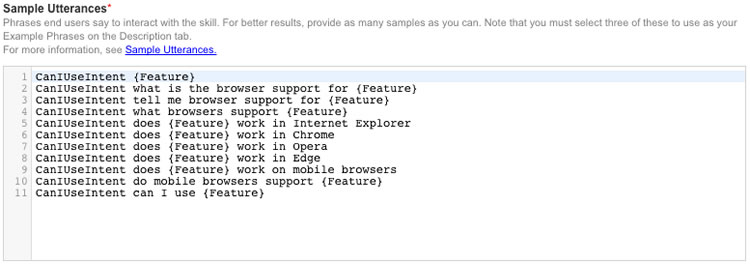
Now it is necessary to specify the service endpoint established earlier in AWS (identified by the ARN).
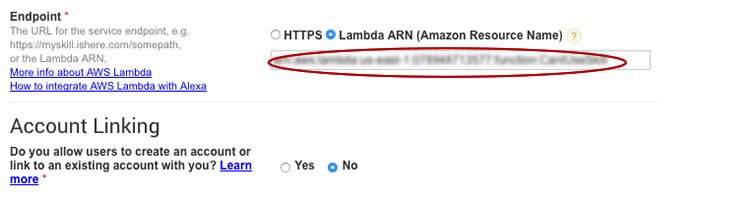
And the skill is ready to test. During development it is easier to test using the web based test pictured below. It will give you the full request and response details. (Note: although "can I use" is not the invocation name, it is one of the accepted utterances once the skill is invoked, thus why it works here.)
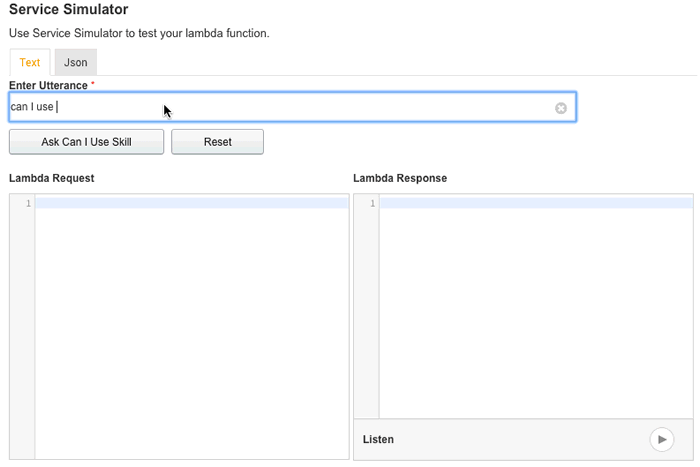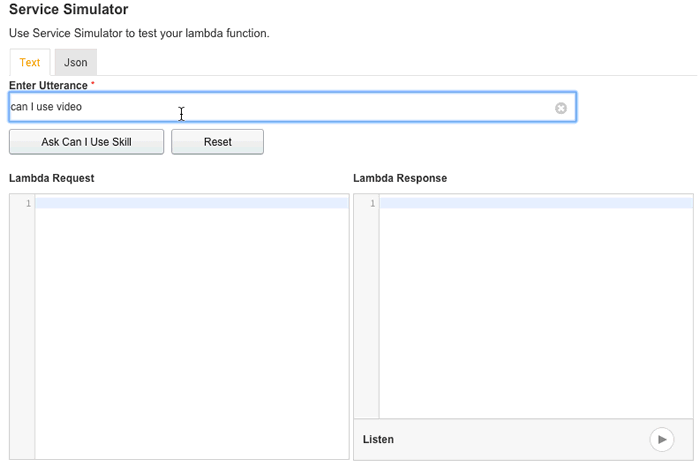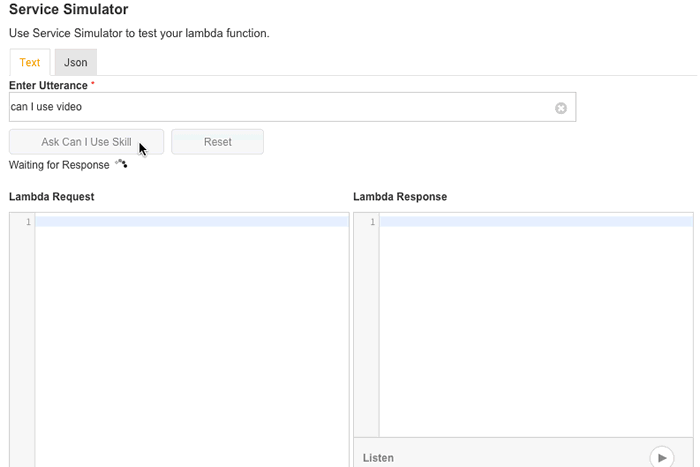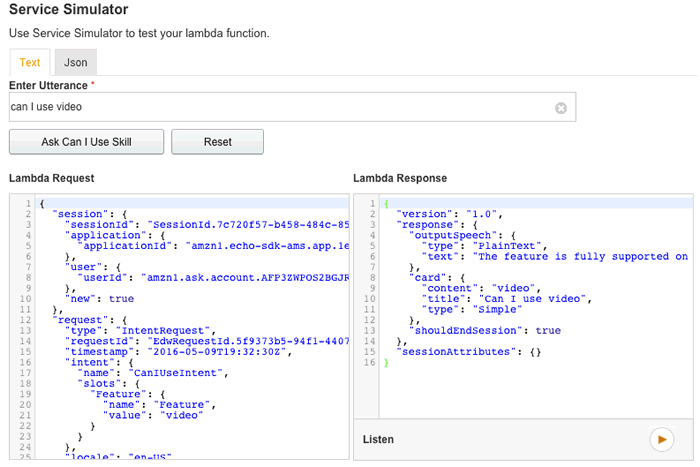
It's important to mention here that, should there be an error or problem of any sort, the "Lambda Response" will simply state the response was invalid. No other details are provided. This is why it's important to separate the code for the response from the Alexa skill code, so that it's easy to test locally. Otherwise, you'll drive yourself crazy trying to figure out exactly where the failure originated.
Once you have a valid response, if you have a device like an Echo that runs Alexa and is hooked to your Amazon account, you can test it. In the video below, I am testing the Can I Use skill I created on my Echo.
In the video, you can hear Alexa respond with the instructions, results for the video element (pictured in the Can I Use screenshot earlier) and a more complex response for web animations (pictured below).
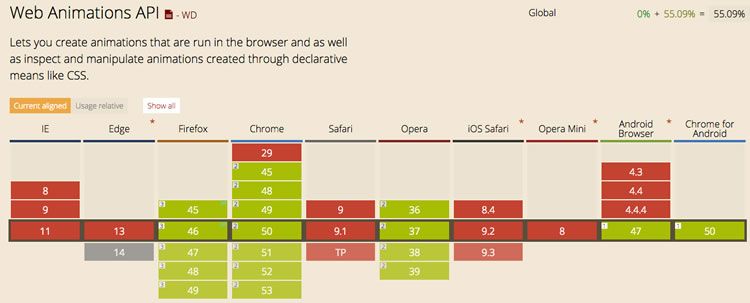
The final step, assuming that you intend to publish your skill publicly, is to add the publishing information. Pay particular attention to your "example phrases" as these will appear in the Alexa app and all of them obviously must work, and the first one should include the invocation name.
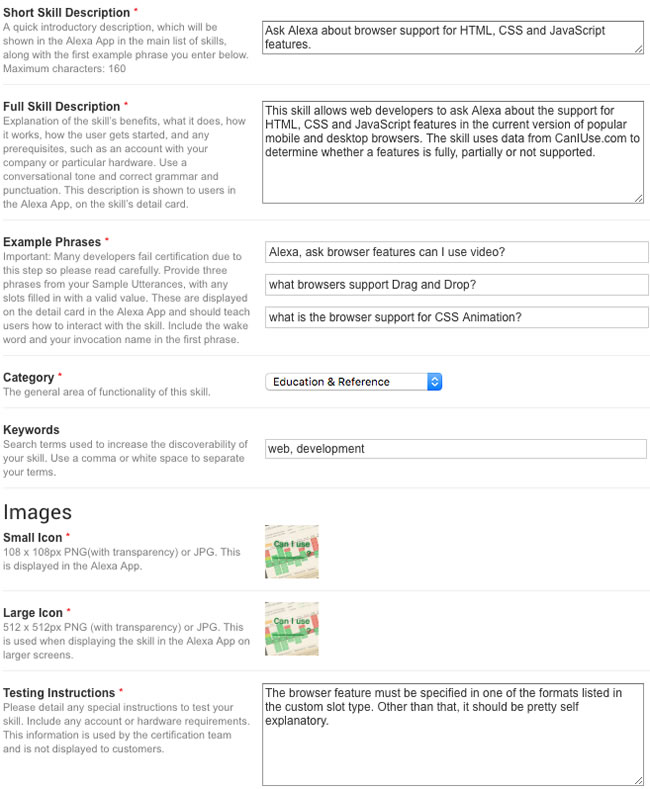
Conclusion
It may seem like a lot of complicated steps, but, in truth, creating new skills for Alexa is actually quite easy. The difficult part is figuring out how to respond in meaningful ways using voice. As a web developer, I'm so used to the ease of presenting complex data visually, that trying to think about how this can be represented in spoken words can be challenging. However, as more and more devices start using voice as a primary means of interaction, it is likely something we'll encounter this more often as developers.
If you want to check out the full code for the Alexa Can I Use skill, it is available here. It is also has been certified and published as a skill by Amazon, so you can add it to your Echo or other Alexa-enabled device.
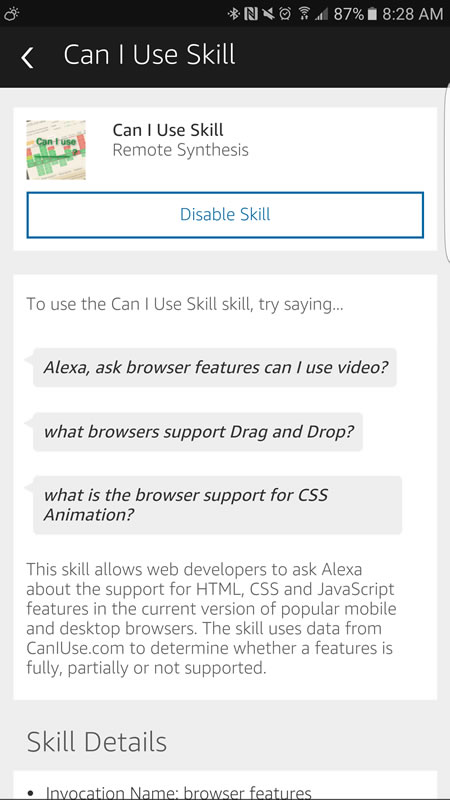
If you have any feedback on how I can improve the skill, please share.

Brian Rinaldi
Brian Rinaldi is a Developer Advocate at Progress focused on the Kinvey mobile backend as a service. You can follow Brian via @remotesynth on Twitter.